API Doc¶
Experiment¶
-
class
xnmt.experiments.ExpGlobal(model_file='{EXP_DIR}/models/{EXP}.mod', log_file='{EXP_DIR}/logs/{EXP}.log', dropout=0.3, weight_noise=0.0, default_layer_dim=512, param_init=bare(GlorotInitializer), bias_init=bare(ZeroInitializer), truncate_dec_batches=False, save_num_checkpoints=1, loss_comb_method='sum', commandline_args={}, placeholders={})[source]¶ Bases:
xnmt.persistence.SerializableAn object that holds global settings that can be referenced by components wherever appropriate.
Parameters: - model_file (
str) – Location to write model file to - log_file (
str) – Location to write log file to - dropout (
Real) – Default dropout probability that should be used by supporting components but can be overwritten - weight_noise (
Real) – Default weight noise level that should be used by supporting components but can be overwritten - default_layer_dim (
Integral) – Default layer dimension that should be used by supporting components but can be overwritten - param_init (
ParamInitializer) – Default parameter initializer that should be used by supporting components but can be overwritten - bias_init (
ParamInitializer) – Default initializer for bias parameters that should be used by supporting components but can be overwritten - truncate_dec_batches (
bool) – whether the decoder drops batch elements as soon as these are masked at some time step. - save_num_checkpoints (
Integral) – save DyNet parameters for the most recent n checkpoints, useful for model averaging/ensembling - loss_comb_method (
str) – method for combining loss across batch elements (‘sum’ or ‘avg’). - commandline_args (
dict) – Holds commandline arguments with which XNMT was launched - placeholders (
Dict[str,Any]) – these will be used as arguments for a format() call applied to every string in the config. For example,placeholders: {"PATH":"/some/path"} will cause each occurence of ``"{PATH}"in a string to be replaced by"/some/path". As a special variable,EXP_DIRcan be specified to overwrite the default location for writing models, logs, and other files.
- model_file (
-
class
xnmt.experiments.Experiment(name, exp_global=bare(ExpGlobal), preproc=None, model=None, train=None, evaluate=None, random_search_report=None, status=None)[source]¶ Bases:
xnmt.persistence.SerializableA default experiment that performs preprocessing, training, and evaluation.
The initializer calls ParamManager.populate(), meaning that model construction should be finalized at this point. __call__() runs the individual steps.
Parameters: - name (
str) – name of experiment - exp_global (
Optional[ExpGlobal]) – global experiment settings - preproc (
Optional[PreprocRunner]) – carry out preprocessing if specified - model (
Optional[TrainableModel]) – The main model. In the case of multitask training, several models must be specified, in which case the models will live not here but inside the training task objects. - train (
Optional[TrainingRegimen]) – The training regimen defines the training loop. - evaluate (
Optional[List[EvalTask]]) – list of tasks to evaluate the model after training finishes. - random_search_report (
Optional[dict]) – When random search is used, this holds the settings that were randomly drawn for documentary purposes. - status (
Optional[str]) – Status of the experiment, will be automatically set to “done” in saved model if the experiment has finished running.
- name (
Model¶
Model Base Classes¶
-
class
xnmt.models.base.TrainableModel[source]¶ Bases:
objectA template class for a basic trainable model, implementing a loss function.
-
class
xnmt.models.base.UnconditionedModel(trg_reader)[source]¶ Bases:
xnmt.models.base.TrainableModelA template class for trainable model that computes target losses without conditioning on other inputs.
Parameters: trg_reader ( InputReader) – target reader-
calc_nll(trg)[source]¶ Calculate loss based on target inputs.
Losses are accumulated only across unmasked timesteps in each batch element.
Parameters: trg ( Union[Batch,Sentence]) – The target, a sentence or a batch of sentences.Return type: ExpressionReturns: A (possibly batched) expression representing the loss.
-
-
class
xnmt.models.base.ConditionedModel(src_reader, trg_reader)[source]¶ Bases:
xnmt.models.base.TrainableModelA template class for a trainable model that computes target losses conditioned on a source input.
Parameters: - src_reader (
InputReader) – source reader - trg_reader (
InputReader) – target reader
- src_reader (
-
class
xnmt.models.base.GeneratorModel(src_reader, trg_reader=None)[source]¶ Bases:
objectA template class for models that can perform inference to generate some kind of output.
Parameters: - src_reader (
InputReader) – source input reader - trg_reader (
Optional[InputReader]) – an optional target input reader, needed in some cases such as n-best scoring
-
generate(src, *args, **kwargs)[source]¶ Generate outputs.
Parameters: - src (
Batch) – batch of source-side inputs - *args –
- **kwargs – Further arguments to be specified by subclasses
Return type: Sequence[ReadableSentence]Returns: output objects
- src (
- src_reader (
-
class
xnmt.models.base.CascadeGenerator(generators)[source]¶ Bases:
xnmt.models.base.GeneratorModel,xnmt.persistence.SerializableA cascade that chains several generator models.
This generator does not support calling
generate()directly. Instead, it’s sub-generators should be accessed and used to generate outputs one by one.Parameters: generators ( Sequence[GeneratorModel]) – list of generators-
generate(*args, **kwargs)[source]¶ Generate outputs.
Parameters: - src – batch of source-side inputs
- *args –
- **kwargs – Further arguments to be specified by subclasses
Return type: Sequence[ReadableSentence]Returns: output objects
-
Translator¶
Embedder¶
-
class
xnmt.modelparts.embedders.Embedder[source]¶ Bases:
objectAn embedder takes in word IDs and outputs continuous vectors.
This can be done on a word-by-word basis, or over a sequence.
-
embed(word)[source]¶ Embed a single word.
Parameters: word ( Any) – This will generally be an integer word ID, but could also be something like a string. It could also be batched, in which case the input will be axnmt.batcher.Batchof integers or other things.Return type: ExpressionReturns: Expression corresponding to the embedding of the word(s).
-
embed_sent(x)[source]¶ Embed a full sentence worth of words. By default, just do a for loop.
Parameters: x ( Any) – This will generally be a list of word IDs, but could also be a list of strings or some other format. It could also be batched, in which case it will be a (possibly masked)xnmt.batcher.BatchobjectReturn type: ExpressionSequenceReturns: An expression sequence representing vectors of each word in the input.
-
choose_vocab(vocab, yaml_path, src_reader, trg_reader)[source]¶ Choose the vocab for the embedder basd on the passed arguments
This is done in order of priority of vocab, model+yaml_path
Parameters: - vocab (
Vocab) – If None, try to obtain fromsrc_readerortrg_reader, depending on theyaml_path - yaml_path (
Path) – Path of this embedder in the component hierarchy. Automatically determined when deserializing the YAML model. - src_reader (
InputReader) – Model’s src_reader, if exists and unambiguous. - trg_reader (
InputReader) – Model’s trg_reader, if exists and unambiguous.
Return type: Returns: chosen vocab
- vocab (
-
choose_vocab_size(vocab_size, vocab, yaml_path, src_reader, trg_reader)[source]¶ Choose the vocab size for the embedder based on the passed arguments
This is done in order of priority of vocab_size, vocab, model+yaml_path
Parameters: - vocab_size (
Integral) – vocab size or None - vocab (
Vocab) – vocab or None - yaml_path (
Path) – Path of this embedder in the component hierarchy. Automatically determined when YAML-deserializing. - src_reader (
InputReader) – Model’s src_reader, if exists and unambiguous. - trg_reader (
InputReader) – Model’s trg_reader, if exists and unambiguous.
Return type: intReturns: chosen vocab size
- vocab_size (
-
-
class
xnmt.modelparts.embedders.DenseWordEmbedder(emb_dim=Ref(path=exp_global.default_layer_dim), weight_noise=Ref(path=exp_global.weight_noise, default=0.0), word_dropout=0.0, fix_norm=None, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549230336040), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549230336488), vocab_size=None, vocab=None, yaml_path='', src_reader=Ref(path=model.src_reader, default=None), trg_reader=Ref(path=model.trg_reader, default=None))[source]¶ Bases:
xnmt.modelparts.embedders.Embedder,xnmt.modelparts.transforms.Linear,xnmt.persistence.SerializableWord embeddings via full matrix.
Parameters: - emb_dim (
Integral) – embedding dimension - weight_noise (
Real) – apply Gaussian noise with given standard deviation to embeddings - word_dropout (
Real) – drop out word types with a certain probability, sampling word types on a per-sentence level, see https://arxiv.org/abs/1512.05287 - fix_norm (
Optional[Real]) – fix the norm of word vectors to be radius r, see https://arxiv.org/abs/1710.01329 - param_init (
ParamInitializer) – how to initialize weight matrices - bias_init (
ParamInitializer) – how to initialize bias vectors - vocab_size (
Optional[Integral]) – vocab size or None - vocab (
Optional[Vocab]) – vocab or None - yaml_path (
Path) – Path of this embedder in the component hierarchy. Automatically set by the YAML deserializer. - src_reader (
Optional[InputReader]) – A reader for the source side. Automatically set by the YAML deserializer. - trg_reader (
Optional[InputReader]) – A reader for the target side. Automatically set by the YAML deserializer.
-
embed(x)[source]¶ Embed a single word.
Parameters: word – This will generally be an integer word ID, but could also be something like a string. It could also be batched, in which case the input will be a xnmt.batcher.Batchof integers or other things.Return type: ExpressionReturns: Expression corresponding to the embedding of the word(s).
- emb_dim (
-
class
xnmt.modelparts.embedders.SimpleWordEmbedder(emb_dim=Ref(path=exp_global.default_layer_dim), weight_noise=Ref(path=exp_global.weight_noise, default=0.0), word_dropout=0.0, fix_norm=None, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549230337328), vocab_size=None, vocab=None, yaml_path=, src_reader=Ref(path=model.src_reader, default=None), trg_reader=Ref(path=model.trg_reader, default=None))[source]¶ Bases:
xnmt.modelparts.embedders.Embedder,xnmt.persistence.SerializableSimple word embeddings via lookup.
Parameters: - emb_dim (
Integral) – embedding dimension - weight_noise (
Real) – apply Gaussian noise with given standard deviation to embeddings - word_dropout (
Real) – drop out word types with a certain probability, sampling word types on a per-sentence level, see https://arxiv.org/abs/1512.05287 - fix_norm (
Optional[Real]) – fix the norm of word vectors to be radius r, see https://arxiv.org/abs/1710.01329 - param_init (
ParamInitializer) – how to initialize lookup matrices - vocab_size (
Optional[Integral]) – vocab size or None - vocab (
Optional[Vocab]) – vocab or None - yaml_path (
Path) – Path of this embedder in the component hierarchy. Automatically set by the YAML deserializer. - src_reader (
Optional[InputReader]) – A reader for the source side. Automatically set by the YAML deserializer. - trg_reader (
Optional[InputReader]) – A reader for the target side. Automatically set by the YAML deserializer.
-
embed(x)[source]¶ Embed a single word.
Parameters: word – This will generally be an integer word ID, but could also be something like a string. It could also be batched, in which case the input will be a xnmt.batcher.Batchof integers or other things.Return type: ExpressionReturns: Expression corresponding to the embedding of the word(s).
- emb_dim (
-
class
xnmt.modelparts.embedders.NoopEmbedder(emb_dim)[source]¶ Bases:
xnmt.modelparts.embedders.Embedder,xnmt.persistence.SerializableThis embedder performs no lookups but only passes through the inputs.
Normally, the input is a Sentence object, which is converted to an expression.
Parameters: emb_dim ( Optional[Integral]) – Size of the inputs-
embed(x)[source]¶ Embed a single word.
Parameters: word – This will generally be an integer word ID, but could also be something like a string. It could also be batched, in which case the input will be a xnmt.batcher.Batchof integers or other things.Return type: ExpressionReturns: Expression corresponding to the embedding of the word(s).
-
embed_sent(x)[source]¶ Embed a full sentence worth of words. By default, just do a for loop.
Parameters: x ( Sentence) – This will generally be a list of word IDs, but could also be a list of strings or some other format. It could also be batched, in which case it will be a (possibly masked)xnmt.batcher.BatchobjectReturn type: ExpressionSequenceReturns: An expression sequence representing vectors of each word in the input.
-
-
class
xnmt.modelparts.embedders.PretrainedSimpleWordEmbedder(filename, emb_dim=Ref(path=exp_global.default_layer_dim), weight_noise=Ref(path=exp_global.weight_noise, default=0.0), word_dropout=0.0, fix_norm=None, vocab=None, yaml_path=, src_reader=Ref(path=model.src_reader, default=None), trg_reader=Ref(path=model.trg_reader, default=None))[source]¶ Bases:
xnmt.modelparts.embedders.SimpleWordEmbedder,xnmt.persistence.SerializableSimple word embeddings via lookup. Initial pretrained embeddings must be supplied in FastText text format.
Parameters: - filename (
str) – Filename for the pretrained embeddings - emb_dim (
Integral) – embedding dimension; if None, use exp_global.default_layer_dim - weight_noise (
Real) – apply Gaussian noise with given standard deviation to embeddings; ifNone, use exp_global.weight_noise - word_dropout (
Real) – drop out word types with a certain probability, sampling word types on a per-sentence level, see https://arxiv.org/abs/1512.05287 - fix_norm (
Optional[Real]) – fix the norm of word vectors to be radius r, see https://arxiv.org/abs/1710.01329 - vocab (
Optional[Vocab]) – vocab or None - yaml_path (
Path) – Path of this embedder in the component hierarchy. Automatically set by the YAML deserializer. - src_reader (
Optional[InputReader]) – A reader for the source side. Automatically set by the YAML deserializer. - trg_reader (
Optional[InputReader]) – A reader for the target side. Automatically set by the YAML deserializer.
- filename (
-
class
xnmt.modelparts.embedders.PositionEmbedder(max_pos, emb_dim=Ref(path=exp_global.default_layer_dim), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549230379864))[source]¶ Bases:
xnmt.modelparts.embedders.Embedder,xnmt.persistence.Serializable-
embed(word)[source]¶ Embed a single word.
Parameters: word – This will generally be an integer word ID, but could also be something like a string. It could also be batched, in which case the input will be a xnmt.batcher.Batchof integers or other things.Returns: Expression corresponding to the embedding of the word(s).
-
embed_sent(sent_len)[source]¶ Embed a full sentence worth of words. By default, just do a for loop.
Parameters: x – This will generally be a list of word IDs, but could also be a list of strings or some other format. It could also be batched, in which case it will be a (possibly masked) xnmt.batcher.BatchobjectReturn type: ExpressionSequenceReturns: An expression sequence representing vectors of each word in the input.
-
Transducer¶
-
class
xnmt.transducers.base.FinalTransducerState(main_expr, cell_expr=None)[source]¶ Bases:
objectRepresents the final encoder state; Currently handles a main (hidden) state and a cell state. If cell state is not provided, it is created as tanh^{-1}(hidden state). Could in the future be extended to handle dimensions other than h and c.
Parameters: - main_expr (
Expression) – expression for hidden state - cell_expr (
Optional[Expression]) – expression for cell state, if exists
- main_expr (
-
class
xnmt.transducers.base.SeqTransducer[source]¶ Bases:
objectA class that transforms one sequence of vectors into another, using
expression_seqs.ExpressionSequenceobjects as inputs and outputs.-
transduce(seq)[source]¶ Parameters should be
expression_seqs.ExpressionSequenceobjects wherever appropriateParameters: seq ( ExpressionSequence) – An expression sequence representing the input to the transductionReturn type: ExpressionSequenceReturns: result of transduction, an expression sequence
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
-
-
class
xnmt.transducers.base.ModularSeqTransducer(input_dim, modules)[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableA sequence transducer that stacks several
xnmt.transducer.SeqTransducerobjects, all of which must accept exactly one argument (anexpression_seqs.ExpressionSequence) in their transduce method.Parameters: - input_dim (
Integral) – input dimension (not required) - modules (
List[SeqTransducer]) – list of SeqTransducer modules
Return the shared parameters of this Serializable class.
This can be overwritten to specify what parameters of this component and its subcomponents are shared. Parameter sharing is performed before any components are initialized, and can therefore only include basic data types that are already present in the YAML file (e.g. # dimensions, etc.) Sharing is performed if at least one parameter is specified and multiple shared parameters don’t conflict. In case of conflict a warning is printed, and no sharing is performed. The ordering of shared parameters is irrelevant. Note also that if a submodule is replaced by a reference, its shared parameters are ignored.
Returns: objects referencing params of this component or a subcompononent e.g.: return [set([".input_dim", ".sub_module.input_dim", ".submodules_list.0.input_dim"])]
-
transduce(seq)[source]¶ Parameters should be
expression_seqs.ExpressionSequenceobjects wherever appropriateParameters: seq ( ExpressionSequence) – An expression sequence representing the input to the transductionReturn type: ExpressionSequenceReturns: result of transduction, an expression sequence
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
- input_dim (
-
class
xnmt.transducers.base.IdentitySeqTransducer[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableA transducer that simply returns the input.
-
class
xnmt.transducers.base.TransformSeqTransducer(transform, downsample_by=1)[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableA sequence transducer that applies a given transformation to the sequence’s tensor representation
Parameters: - transform (
Transform) – the Transform to apply to the sequence - downsample_by (
Integral) – if > 1, downsample the sequence via appropriate reshapes. The transform must accept a respectively larger hidden dimension.
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
- transform (
RNN¶
-
class
xnmt.transducers.recurrent.UniLSTMState(network, prev=None, c=None, h=None)[source]¶ Bases:
objectState object for UniLSTMSeqTransducer.
-
class
xnmt.transducers.recurrent.UniLSTMSeqTransducer(layers=1, input_dim=Ref(path=exp_global.default_layer_dim), hidden_dim=Ref(path=exp_global.default_layer_dim), dropout=Ref(path=exp_global.dropout, default=0.0), weightnoise_std=Ref(path=exp_global.weight_noise, default=0.0), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298518616), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298518952), yaml_path=, decoder_input_dim=Ref(path=exp_global.default_layer_dim, default=None), decoder_input_feeding=True)[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableThis implements a single LSTM layer based on the memory-friendly dedicated DyNet nodes. It works similar to DyNet’s CompactVanillaLSTMBuilder, but in addition supports taking multiple inputs that are concatenated on-the-fly.
Parameters: - layers (int) – number of layers
- input_dim (int) – input dimension
- hidden_dim (int) – hidden dimension
- dropout (float) – dropout probability
- weightnoise_std (float) – weight noise standard deviation
- param_init (ParamInitializer) – how to initialize weight matrices
- bias_init (ParamInitializer) – how to initialize bias vectors
- yaml_path (str) –
- decoder_input_dim (int) – input dimension of the decoder; if
yaml_pathcontains ‘decoder’ anddecoder_input_feedingis True, this will be added toinput_dim - decoder_input_feeding (bool) – whether this transducer is part of an input-feeding decoder; cf.
decoder_input_dim
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
-
transduce(expr_seq)[source]¶ transduce the sequence, applying masks if given (masked timesteps simply copy previous h / c)
Parameters: expr_seq ( ExpressionSequence) – expression sequence or list of expression sequences (where each inner list will be concatenated)Return type: ExpressionSequenceReturns: expression sequence
-
class
xnmt.transducers.recurrent.BiLSTMSeqTransducer(layers=1, input_dim=Ref(path=exp_global.default_layer_dim), hidden_dim=Ref(path=exp_global.default_layer_dim), dropout=Ref(path=exp_global.dropout, default=0.0), weightnoise_std=Ref(path=exp_global.weight_noise, default=0.0), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298519848), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298577816), forward_layers=None, backward_layers=None)[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableThis implements a bidirectional LSTM and requires about 8.5% less memory per timestep than DyNet’s CompactVanillaLSTMBuilder due to avoiding concat operations. It uses 2
xnmt.lstm.UniLSTMSeqTransducerobjects in each layer.Parameters: - layers (int) – number of layers
- input_dim (int) – input dimension
- hidden_dim (int) – hidden dimension
- dropout (float) – dropout probability
- weightnoise_std (float) – weight noise standard deviation
- param_init (
ParamInitializer) – axnmt.param_init.ParamInitializeror list ofxnmt.param_init.ParamInitializerobjects specifying how to initialize weight matrices. If a list is given, each entry denotes one layer. - bias_init (
ParamInitializer) – axnmt.param_init.ParamInitializeror list ofxnmt.param_init.ParamInitializerobjects specifying how to initialize bias vectors. If a list is given, each entry denotes one layer. - forward_layers (
Optional[Sequence[UniLSTMSeqTransducer]]) – set automatically - backward_layers (
Optional[Sequence[UniLSTMSeqTransducer]]) – set automatically
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
-
class
xnmt.transducers.recurrent.CustomLSTMSeqTransducer(layers, input_dim, hidden_dim, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298578264), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298578600))[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableThis implements an LSTM builder based on elementary DyNet operations. It is more memory-hungry than the compact LSTM, but can be extended more easily. It currently does not support dropout or multiple layers and is mostly meant as a starting point for LSTM extensions.
Parameters: - layers (int) – number of layers
- input_dim (int) – input dimension; if None, use exp_global.default_layer_dim
- hidden_dim (int) – hidden dimension; if None, use exp_global.default_layer_dim
- param_init (
ParamInitializer) – axnmt.param_init.ParamInitializeror list ofxnmt.param_init.ParamInitializerobjects specifying how to initialize weight matrices. If a list is given, each entry denotes one layer. If None, useexp_global.param_init - bias_init (
ParamInitializer) – axnmt.param_init.ParamInitializeror list ofxnmt.param_init.ParamInitializerobjects specifying how to initialize bias vectors. If a list is given, each entry denotes one layer. If None, useexp_global.param_init
-
class
xnmt.transducers.pyramidal.PyramidalLSTMSeqTransducer(layers=1, input_dim=Ref(path=exp_global.default_layer_dim), hidden_dim=Ref(path=exp_global.default_layer_dim), downsampling_method='concat', reduce_factor=2, dropout=Ref(path=exp_global.dropout, default=0.0), builder_layers=None)[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableBuilder for pyramidal RNNs that delegates to
UniLSTMSeqTransducerobjects and wires them together. See https://arxiv.org/abs/1508.01211Every layer (except the first) reduces sequence length by the specified factor.
Parameters: - layers (
Integral) – number of layers - input_dim (
Integral) – input dimension - hidden_dim (
Integral) – hidden dimension - downsampling_method (
str) – how to perform downsampling (concat|skip) - reduce_factor (
Union[Integral,Sequence[Integral]]) – integer, or list of ints (different skip for each layer) - dropout (
float) – dropout probability; if None, use exp_global.dropout - builder_layers (
Optional[Any]) – set automatically
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
- layers (
-
class
xnmt.transducers.residual.ResidualSeqTransducer(child, input_dim, layer_norm=False, dropout=Ref(path=exp_global.dropout, default=0.0))[source]¶ Bases:
xnmt.transducers.base.SeqTransducer,xnmt.persistence.SerializableA sequence transducer that wraps a
xnmt.transducers.base.SeqTransducerin an additive residual connection, and optionally performs some variety of normalization.Parameters: - the child transducer to wrap (child) –
- layer_norm (
bool) – whether to perform layer normalization - dropout – whether to apply residual dropout
-
transduce(seq)[source]¶ Parameters should be
expression_seqs.ExpressionSequenceobjects wherever appropriateParameters: seq ( ExpressionSequence) – An expression sequence representing the input to the transductionReturn type: ExpressionSequenceReturns: result of transduction, an expression sequence
-
get_final_states()[source]¶ Returns: A list of FinalTransducerState objects corresponding to a fixed-dimension representation of the input, after having invoked transduce()
Return type: List[FinalTransducerState]
Attender¶
-
class
xnmt.modelparts.attenders.Attender[source]¶ Bases:
objectA template class for functions implementing attention.
-
init_sent(sent)[source]¶ Args: sent: the encoder states, aka keys and values. Usually but not necessarily an
expression_seqs.ExpressionSequenceReturn type: None
-
calc_attention(state)[source]¶ Compute attention weights.
Parameters: state ( Expression) – the current decoder state, aka query, for which to compute the weights.Return type: ExpressionReturns: DyNet expression containing normalized attention scores
-
calc_context(state, attention=None)[source]¶ Compute weighted sum.
Parameters: - state (
Expression) – the current decoder state, aka query, for which to compute the weighted sum. - attention (
Optional[Expression]) – the attention vector to use. if not given it is calculated from the state.
Return type: Expression- state (
-
-
class
xnmt.modelparts.attenders.MlpAttender(input_dim=Ref(path=exp_global.default_layer_dim), state_dim=Ref(path=exp_global.default_layer_dim), hidden_dim=Ref(path=exp_global.default_layer_dim), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549180320064), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549180320512), truncate_dec_batches=Ref(path=exp_global.truncate_dec_batches, default=False))[source]¶ Bases:
xnmt.modelparts.attenders.Attender,xnmt.persistence.SerializableImplements the attention model of Bahdanau et. al (2014)
Parameters: - input_dim (
Integral) – input dimension - state_dim (
Integral) – dimension of state inputs - hidden_dim (
Integral) – hidden MLP dimension - param_init (
ParamInitializer) – how to initialize weight matrices - bias_init (
ParamInitializer) – how to initialize bias vectors - truncate_dec_batches (
bool) – whether the decoder drops batch elements as soon as these are masked at some time step.
- input_dim (
-
class
xnmt.modelparts.attenders.DotAttender(scale=True, truncate_dec_batches=Ref(path=exp_global.truncate_dec_batches, default=False))[source]¶ Bases:
xnmt.modelparts.attenders.Attender,xnmt.persistence.SerializableImplements dot product attention of https://arxiv.org/abs/1508.04025 Also (optionally) perform scaling of https://arxiv.org/abs/1706.03762
Parameters: - scale (
bool) – whether to perform scaling - truncate_dec_batches (
bool) – currently unsupported
- scale (
-
class
xnmt.modelparts.attenders.BilinearAttender(input_dim=Ref(path=exp_global.default_layer_dim), state_dim=Ref(path=exp_global.default_layer_dim), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549180321128), truncate_dec_batches=Ref(path=exp_global.truncate_dec_batches, default=False))[source]¶ Bases:
xnmt.modelparts.attenders.Attender,xnmt.persistence.SerializableImplements a bilinear attention, equivalent to the ‘general’ linear attention of https://arxiv.org/abs/1508.04025
Parameters: - input_dim (
Integral) – input dimension; if None, use exp_global.default_layer_dim - state_dim (
Integral) – dimension of state inputs; if None, use exp_global.default_layer_dim - param_init (
ParamInitializer) – how to initialize weight matrices; if None, useexp_global.param_init - truncate_dec_batches (
bool) – currently unsupported
- input_dim (
-
class
xnmt.modelparts.attenders.LatticeBiasedMlpAttender(input_dim=Ref(path=exp_global.default_layer_dim), state_dim=Ref(path=exp_global.default_layer_dim), hidden_dim=Ref(path=exp_global.default_layer_dim), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549181218544), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549181218152), truncate_dec_batches=Ref(path=exp_global.truncate_dec_batches, default=False))[source]¶ Bases:
xnmt.modelparts.attenders.MlpAttender,xnmt.persistence.SerializableModified MLP attention, where lattices are assumed as input and the attention is biased toward confident nodes.
Parameters: - input_dim (
Integral) – input dimension - state_dim (
Integral) – dimension of state inputs - hidden_dim (
Integral) – hidden MLP dimension - param_init (
ParamInitializer) – how to initialize weight matrices - bias_init (
ParamInitializer) – how to initialize bias vectors - truncate_dec_batches (
bool) – whether the decoder drops batch elements as soon as these are masked at some time step.
- input_dim (
Decoder¶
-
class
xnmt.modelparts.decoders.Decoder[source]¶ Bases:
objectA template class to convert a prefix of previously generated words and a context vector into a probability distribution over possible next words.
-
class
xnmt.modelparts.decoders.DecoderState[source]¶ Bases:
objectA state that holds whatever information is required for the decoder. Child classes must implement the as_vector() method, which will be used by e.g. the attention mechanism
-
class
xnmt.modelparts.decoders.AutoRegressiveDecoderState(rnn_state=None, context=None)[source]¶ Bases:
xnmt.modelparts.decoders.DecoderStateA state holding all the information needed for AutoRegressiveDecoder
Parameters: - rnn_state – a DyNet RNN state
- context – a DyNet expression
-
class
xnmt.modelparts.decoders.AutoRegressiveDecoder(input_dim=Ref(path=exp_global.default_layer_dim), embedder=bare(SimpleWordEmbedder), input_feeding=True, bridge=bare(CopyBridge), rnn=bare(UniLSTMSeqTransducer), transform=bare(AuxNonLinear), scorer=bare(Softmax), truncate_dec_batches=Ref(path=exp_global.truncate_dec_batches, default=False))[source]¶ Bases:
xnmt.modelparts.decoders.Decoder,xnmt.persistence.SerializableStandard autoregressive-decoder.
Parameters: - input_dim (
Integral) – input dimension - embedder (
Embedder) – embedder for target words - input_feeding (
bool) – whether to activate input feeding - bridge (
Bridge) – how to initialize decoder state - rnn (
UniLSTMSeqTransducer) – recurrent decoder - transform (
Transform) – a layer of transformation between rnn and output scorer - scorer (
Scorer) – the method of scoring the output (usually softmax) - truncate_dec_batches (
bool) – whether the decoder drops batch elements as soon as these are masked at some time step.
Return the shared parameters of this Serializable class.
This can be overwritten to specify what parameters of this component and its subcomponents are shared. Parameter sharing is performed before any components are initialized, and can therefore only include basic data types that are already present in the YAML file (e.g. # dimensions, etc.) Sharing is performed if at least one parameter is specified and multiple shared parameters don’t conflict. In case of conflict a warning is printed, and no sharing is performed. The ordering of shared parameters is irrelevant. Note also that if a submodule is replaced by a reference, its shared parameters are ignored.
Returns: objects referencing params of this component or a subcompononent e.g.: return [set([".input_dim", ".sub_module.input_dim", ".submodules_list.0.input_dim"])]
-
initial_state(enc_final_states, ss)[source]¶ Get the initial state of the decoder given the encoder final states.
Parameters: - enc_final_states (
Any) – The encoder final states. Usually but not necessarily anxnmt.expression_sequence.ExpressionSequence - ss (
Any) – first input
Return type: Returns: initial decoder state
- enc_final_states (
-
add_input(dec_state, trg_word)[source]¶ Add an input and return a new update the state.
Parameters: - dec_state (
AutoRegressiveDecoderState) – An object containing the current state. - trg_word (
Any) – The word to input.
Return type: Returns: The updated decoder state.
- dec_state (
- input_dim (
Bridge¶
-
class
xnmt.modelparts.bridges.Bridge[source]¶ Bases:
objectResponsible for initializing the decoder LSTM, based on the final encoder state
-
decoder_init(enc_final_states)[source]¶ Parameters: enc_final_states ( Sequence[FinalTransducerState]) – list of final states for each encoder layerReturn type: List[Expression]Returns: list of initial hidden and cell expressions for each layer. List indices 0..n-1 hold hidden states, n..2n-1 hold cell states.
-
-
class
xnmt.modelparts.bridges.NoBridge(dec_layers=1, dec_dim=Ref(path=exp_global.default_layer_dim))[source]¶ Bases:
xnmt.modelparts.bridges.Bridge,xnmt.persistence.SerializableThis bridge initializes the decoder with zero vectors, disregarding the encoder final states.
Parameters: - dec_layers (
Integral) – number of decoder layers to initialize - dec_dim (
Integral) – hidden dimension of decoder states
-
decoder_init(enc_final_states)[source]¶ Parameters: enc_final_states ( Sequence[FinalTransducerState]) – list of final states for each encoder layerReturn type: List[Expression]Returns: list of initial hidden and cell expressions for each layer. List indices 0..n-1 hold hidden states, n..2n-1 hold cell states.
- dec_layers (
-
class
xnmt.modelparts.bridges.CopyBridge(dec_layers=1, dec_dim=Ref(path=exp_global.default_layer_dim))[source]¶ Bases:
xnmt.modelparts.bridges.Bridge,xnmt.persistence.SerializableThis bridge copies final states from the encoder to the decoder initial states. Requires that: - encoder / decoder dimensions match for every layer - num encoder layers >= num decoder layers (if unequal, we disregard final states at the encoder bottom)
Parameters: - dec_layers (
Integral) – number of decoder layers to initialize - dec_dim (
Integral) – hidden dimension of decoder states
-
decoder_init(enc_final_states)[source]¶ Parameters: enc_final_states ( Sequence[FinalTransducerState]) – list of final states for each encoder layerReturn type: List[Expression]Returns: list of initial hidden and cell expressions for each layer. List indices 0..n-1 hold hidden states, n..2n-1 hold cell states.
- dec_layers (
-
class
xnmt.modelparts.bridges.LinearBridge(dec_layers=1, enc_dim=Ref(path=exp_global.default_layer_dim), dec_dim=Ref(path=exp_global.default_layer_dim), param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549230233248), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549230233752), projector=None)[source]¶ Bases:
xnmt.modelparts.bridges.Bridge,xnmt.persistence.SerializableThis bridge does a linear transform of final states from the encoder to the decoder initial states. Requires that num encoder layers >= num decoder layers (if unequal, we disregard final states at the encoder bottom)
Parameters: - dec_layers (
Integral) – number of decoder layers to initialize - enc_dim (
Integral) – hidden dimension of encoder states - dec_dim (
Integral) – hidden dimension of decoder states - param_init (
ParamInitializer) – how to initialize weight matrices; if None, useexp_global.param_init - bias_init (
ParamInitializer) – how to initialize bias vectors; if None, useexp_global.bias_init - projector (
Optional[Linear]) – linear projection (created automatically)
-
decoder_init(enc_final_states)[source]¶ Parameters: enc_final_states ( Sequence[FinalTransducerState]) – list of final states for each encoder layerReturn type: List[Expression]Returns: list of initial hidden and cell expressions for each layer. List indices 0..n-1 hold hidden states, n..2n-1 hold cell states.
- dec_layers (
Transform¶
-
class
xnmt.modelparts.transforms.Transform[source]¶ Bases:
objectA class of transforms that change a dynet expression into another.
-
class
xnmt.modelparts.transforms.Identity[source]¶ Bases:
xnmt.modelparts.transforms.Transform,xnmt.persistence.SerializableIdentity transform. For use when you think it might be a better idea to not perform a specific transform in a place where you would normally do one.
-
class
xnmt.modelparts.transforms.Linear(input_dim=Ref(path=exp_global.default_layer_dim), output_dim=Ref(path=exp_global.default_layer_dim), bias=True, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298961656), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298961208))[source]¶ Bases:
xnmt.modelparts.transforms.Transform,xnmt.persistence.SerializableLinear projection with optional bias.
Parameters: - input_dim (
Integral) – input dimension - output_dim (
Integral) – hidden dimension - bias (
bool) – whether to add a bias - param_init (
ParamInitializer) – how to initialize weight matrices - bias_init (
ParamInitializer) – how to initialize bias vectors
- input_dim (
-
class
xnmt.modelparts.transforms.NonLinear(input_dim=Ref(path=exp_global.default_layer_dim), output_dim=Ref(path=exp_global.default_layer_dim), bias=True, activation='tanh', param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298962104), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298962384))[source]¶ Bases:
xnmt.modelparts.transforms.Transform,xnmt.persistence.SerializableLinear projection with optional bias and non-linearity.
Parameters: - input_dim (
Integral) – input dimension - output_dim (
Integral) – hidden dimension - bias (
bool) – whether to add a bias - activation (
str) – One oftanh,relu,sigmoid,elu,selu,asinhoridentity. - param_init (
ParamInitializer) – how to initialize weight matrices - bias_init (
ParamInitializer) – how to initialize bias vectors
- input_dim (
-
class
xnmt.modelparts.transforms.AuxNonLinear(input_dim=Ref(path=exp_global.default_layer_dim), output_dim=Ref(path=exp_global.default_layer_dim), aux_input_dim=Ref(path=exp_global.default_layer_dim), bias=True, activation='tanh', param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298516712), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298517160))[source]¶ Bases:
xnmt.modelparts.transforms.NonLinear,xnmt.persistence.SerializableNonLinear with an additional auxiliary input.
Parameters: - input_dim (
Integral) – input dimension - output_dim (
Integral) – hidden dimension - aux_input_dim (
Integral) – auxiliary input dimension. The actual input dimension is aux_input_dim + input_dim. This is useful for when you want to do something like input feeding. - bias (
bool) – whether to add a bias - activation (
str) – One oftanh,relu,sigmoid,elu,selu,asinhoridentity. - param_init (
ParamInitializer) – how to initialize weight matrices - bias_init (
ParamInitializer) – how to initialize bias vectors
- input_dim (
-
class
xnmt.modelparts.transforms.MLP(input_dim=Ref(path=exp_global.default_layer_dim), hidden_dim=Ref(path=exp_global.default_layer_dim), output_dim=Ref(path=exp_global.default_layer_dim), bias=True, activation='tanh', hidden_layers=1, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549298517720), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549298518168), layers=None)[source]¶ Bases:
xnmt.modelparts.transforms.Transform,xnmt.persistence.SerializableA multi-layer perceptron. Defined as one or more NonLinear transforms of equal hidden dimension and type, then a Linear transform to the output dimension.
-
class
xnmt.modelparts.transforms.Cwise(op='rectify')[source]¶ Bases:
xnmt.modelparts.transforms.Transform,xnmt.persistence.SerializableA component-wise transformation that can be an arbitrary unary DyNet operation.
Parameters: op ( str) – arbitrary unary DyNet node
Scorer¶
-
class
xnmt.modelparts.scorers.Scorer[source]¶ Bases:
objectA template class of things that take in a vector and produce a score over discrete output items.
-
calc_scores(x)[source]¶ Calculate the score of each discrete decision, where the higher the score is the better the model thinks a decision is. These often correspond to unnormalized log probabilities.
Parameters: x ( Expression) – The vector used to make the predictionReturn type: Expression
-
best_k(x, k, normalize_scores=False)[source]¶ Returns a list of the k items with the highest scores. The items may not be in sorted order.
Parameters: - x (
Expression) – The vector used to make the prediction - k (
Integral) – Number of items to return - normalize_scores (
bool) – whether to normalize the scores
- x (
-
calc_probs(x)[source]¶ Calculate the normalized probability of a decision.
Parameters: x ( Expression) – The vector used to make the predictionReturn type: Expression
-
-
class
xnmt.modelparts.scorers.Softmax(input_dim=Ref(path=exp_global.default_layer_dim), vocab_size=None, vocab=None, trg_reader=Ref(path=model.trg_reader, default=None), label_smoothing=0.0, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549230289472), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549230289920), output_projector=None)[source]¶ Bases:
xnmt.modelparts.scorers.Scorer,xnmt.persistence.SerializableA class that does an affine transform from the input to the vocabulary size, and calculates a softmax.
Note that all functions in this class rely on calc_scores(), and thus this class can be sub-classed by any other class that has an alternative method for calculating un-normalized log probabilities by simply overloading the calc_scores() function.
Parameters: - input_dim (
Integral) – Size of the input vector - vocab_size (
Optional[Integral]) – Size of the vocab to predict - vocab (
Optional[Vocab]) – A vocab object from which the vocab size can be derived automatically - trg_reader (
Optional[InputReader]) – An input reader for the target, which can be used to derive the vocab size - label_smoothing (
Real) – Whether to apply label smoothing (a value of 0.1 is good if so) - param_init (
ParamInitializer) – How to initialize the parameters - bias_init (
ParamInitializer) – How to initialize the bias - output_projector (
Optional[Linear]) – The projection to be used before the output
-
calc_scores(x)[source]¶ Calculate the score of each discrete decision, where the higher the score is the better the model thinks a decision is. These often correspond to unnormalized log probabilities.
Parameters: x ( Expression) – The vector used to make the predictionReturn type: Expression
-
best_k(x, k, normalize_scores=False)[source]¶ Returns a list of the k items with the highest scores. The items may not be in sorted order.
Parameters: - x (
Expression) – The vector used to make the prediction - k (
Integral) – Number of items to return - normalize_scores (
bool) – whether to normalize the scores
- x (
-
sample(x, n, temperature=1.0)[source]¶ Return samples from the scores that are treated as probability distributions.
-
can_loss_be_derived_from_scores()[source]¶ This method can be used to determine whether dy.pickneglogsoftmax can be used to quickly calculate the loss value. If False, then the calc_loss method should (1) calc log_softmax, (2) perform necessary modification, (3) pick the loss
-
calc_loss(x, y)[source]¶ Calculate the loss incurred by making a particular decision.
Parameters: - x (
Expression) – The vector used to make the prediction - y (
Union[Integral,List[Integral]]) – The correct label(s)
Return type: Expression- x (
- input_dim (
-
class
xnmt.modelparts.scorers.LexiconSoftmax(input_dim=Ref(path=exp_global.default_layer_dim), vocab_size=None, vocab=None, trg_reader=Ref(path=model.trg_reader, default=None), attender=Ref(path=model.attender), label_smoothing=0.0, param_init=Ref(path=exp_global.param_init, default=GlorotInitializer@140549230290480), bias_init=Ref(path=exp_global.bias_init, default=ZeroInitializer@140549230290928), output_projector=None, lexicon_file=None, lexicon_alpha=0.001, lexicon_type='bias', coef_predictor=None, src_vocab=Ref(path=model.src_reader.vocab, default=None))[source]¶ Bases:
xnmt.modelparts.scorers.Softmax,xnmt.persistence.SerializableA subclass of the softmax class that can make use of an external lexicon probability as described in: http://anthology.aclweb.org/D/D16/D16-1162.pdf
Parameters: - input_dim (
Integral) – Size of the input vector - vocab_size (
Optional[Integral]) – Size of the vocab to predict - vocab (
Optional[Vocab]) – A vocab object from which the vocab size can be derived automatically - trg_reader (
Optional[InputReader]) – An input reader for the target, which can be used to derive the vocab size - label_smoothing (
Real) – Whether to apply label smoothing (a value of 0.1 is good if so) - param_init (
ParamInitializer) – How to initialize the parameters - bias_init (
ParamInitializer) – How to initialize the bias - output_projector (
Optional[Linear]) – The projection to be used before the output - lexicon_file – A file containing “trg src p(trg|src)”
- lexicon_alpha – smoothing constant for bias method
- lexicon_type – Either bias or linear method
-
calc_scores(x)[source]¶ Calculate the score of each discrete decision, where the higher the score is the better the model thinks a decision is. These often correspond to unnormalized log probabilities.
Parameters: x ( Expression) – The vector used to make the predictionReturn type: Expression
-
calc_probs(x)[source]¶ Calculate the normalized probability of a decision.
Parameters: x ( Expression) – The vector used to make the predictionReturn type: Expression
- input_dim (
SequenceLabeler¶
-
class
xnmt.models.sequence_labelers.SeqLabeler(src_reader, trg_reader, src_embedder=bare(SimpleWordEmbedder), encoder=bare(BiLSTMSeqTransducer), transform=bare(NonLinear), scorer=bare(Softmax), inference=bare(IndependentOutputInference), auto_cut_pad=False)[source]¶ Bases:
xnmt.models.base.ConditionedModel,xnmt.models.base.GeneratorModel,xnmt.persistence.Serializable,xnmt.reports.ReportableA simple sequence labeler based on an encoder and an output softmax layer.
Parameters: - src_reader (
InputReader) – A reader for the source side. - trg_reader (
InputReader) – A reader for the target side. - src_embedder (
Embedder) – A word embedder for the input language - encoder (
SeqTransducer) – An encoder to generate encoded inputs - transform (
Transform) – A transform to be applied before making predictions - scorer (
Scorer) – The class to actually make predictions - inference (
Inference) – The inference method used for this model - auto_cut_pad (
bool) – IfTrue, cut or pad target sequences so the match the length of the encoded inputs. IfFalse, an error is thrown if there is a length mismatch.
Return the shared parameters of this Serializable class.
This can be overwritten to specify what parameters of this component and its subcomponents are shared. Parameter sharing is performed before any components are initialized, and can therefore only include basic data types that are already present in the YAML file (e.g. # dimensions, etc.) Sharing is performed if at least one parameter is specified and multiple shared parameters don’t conflict. In case of conflict a warning is printed, and no sharing is performed. The ordering of shared parameters is irrelevant. Note also that if a submodule is replaced by a reference, its shared parameters are ignored.
Return type: Sequence[Set[str]]Returns: objects referencing params of this component or a subcompononent e.g.: return [set([".input_dim", ".sub_module.input_dim", ".submodules_list.0.input_dim"])]
-
calc_nll(src, trg)[source]¶ Calculate loss based on input-output pairs.
Losses are accumulated only across unmasked timesteps in each batch element.
Parameters: Return type: ExpressionReturns: A (possibly batched) expression representing the loss.
-
generate(src, normalize_scores=False)[source]¶ Generate outputs.
Parameters: - src (
Batch) – batch of source-side inputs - *args –
- **kwargs – Further arguments to be specified by subclasses
Return type: Sequence[ReadableSentence]Returns: output objects
- src (
- src_reader (
Classifier¶
-
class
xnmt.models.classifiers.SequenceClassifier(src_reader, trg_reader, src_embedder=bare(SimpleWordEmbedder), encoder=bare(BiLSTMSeqTransducer), inference=bare(IndependentOutputInference), transform=bare(NonLinear), scorer=bare(Softmax))[source]¶ Bases:
xnmt.models.base.ConditionedModel,xnmt.models.base.GeneratorModel,xnmt.persistence.SerializableA sequence classifier.
Runs embeddings through an encoder, feeds the average over all encoder outputs to a transform and scoring layer.
Parameters: - src_reader (
InputReader) – A reader for the source side. - trg_reader (
InputReader) – A reader for the target side. - src_embedder (
Embedder) – A word embedder for the input language - encoder (
SeqTransducer) – An encoder to generate encoded inputs - inference – how to perform inference
- transform (
Transform) – A transform performed before the scoring function - scorer (
Scorer) – A scoring function over the multiple choices
Return the shared parameters of this Serializable class.
This can be overwritten to specify what parameters of this component and its subcomponents are shared. Parameter sharing is performed before any components are initialized, and can therefore only include basic data types that are already present in the YAML file (e.g. # dimensions, etc.) Sharing is performed if at least one parameter is specified and multiple shared parameters don’t conflict. In case of conflict a warning is printed, and no sharing is performed. The ordering of shared parameters is irrelevant. Note also that if a submodule is replaced by a reference, its shared parameters are ignored.
Returns: objects referencing params of this component or a subcompononent e.g.: return [set([".input_dim", ".sub_module.input_dim", ".submodules_list.0.input_dim"])]
- src_reader (
Loss¶
Loss¶
-
class
xnmt.losses.FactoredLossExpr(init_loss=None)[source]¶ Bases:
objectLoss consisting of (possibly batched) DyNet expressions, with one expression per loss factor.
Used to represent losses within a training step.
Parameters: init_loss ( Optional[Dict[str,Expression]]) – initial loss values-
compute(comb_method='sum')[source]¶ Compute loss as DyNet expression by summing over factors and batch elements.
Parameters: comb_method ( str) – method for combining loss across batch elements (‘sum’ or ‘avg’).Return type: ExpressionReturns: Scalar DyNet expression.
-
value()[source]¶ Get list of per-batch-element loss values, summed over factors.
Return type: List[float]Returns: List of same length as batch-size.
-
get_factored_loss_val(comb_method='sum')[source]¶ Create factored loss values by calling
.value()for each DyNet loss expression and applying batch combination.Parameters: comb_method ( str) – method for combining loss across batch elements (‘sum’ or ‘avg’).Return type: FactoredLossValReturns: Factored loss values.
-
-
class
xnmt.losses.FactoredLossVal(loss_dict=None)[source]¶ Bases:
objectLoss consisting of (unbatched) float values, with one value per loss factor.
Used to represent losses accumulated across several training steps.
LossCalculator¶
-
class
xnmt.loss_calculators.LossCalculator[source]¶ Bases:
objectA template class implementing the training strategy and corresponding loss calculation.
-
class
xnmt.loss_calculators.MLELoss[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.loss_calculators.LossCalculatorMax likelihood loss calculator.
-
class
xnmt.loss_calculators.GlobalFertilityLoss[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.loss_calculators.LossCalculatorA fertility loss according to Cohn+, 2016. Incorporating Structural Alignment Biases into an Attentional Neural Translation Model
-
class
xnmt.loss_calculators.CompositeLoss(pt_losses, loss_weight=None)[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.loss_calculators.LossCalculatorSumming losses from multiple LossCalculator.
-
class
xnmt.loss_calculators.ReinforceLoss(baseline=None, evaluation_metric=bare(FastBLEUEvaluator), search_strategy=bare(SamplingSearch), inv_eval=True, decoder_hidden_dim=Ref(path=exp_global.default_layer_dim))[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.loss_calculators.LossCalculatorReinforce Loss according to Ranzato+, 2015. SEQUENCE LEVEL TRAINING WITH RECURRENT NEURAL NETWORKS.
(This is not the MIXER algorithm)
-
class
xnmt.loss_calculators.MinRiskLoss(evaluation_metric=bare(FastBLEUEvaluator), alpha=0.005, inv_eval=True, unique_sample=True, search_strategy=bare(SamplingSearch))[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.loss_calculators.LossCalculator
-
class
xnmt.loss_calculators.FeedbackLoss(child_loss=bare(MLELoss), repeat=1)[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.loss_calculators.LossCalculatorA loss that first calculates a standard loss function, then feeds it back to the model using the model.additional_loss function.
Parameters: - child_loss (
LossCalculator) – The loss that will be fed back to the model - repeat (
Integral) – Repeat the process multiple times and use the sum of the losses. This is useful when there is some non-determinism (such as sampling in the encoder, etc.)
- child_loss (
Training¶
TrainingRegimen¶
-
class
xnmt.train.regimens.TrainingRegimen[source]¶ Bases:
objectA training regimen is a class that implements a training loop.
-
run_training(save_fct)[source]¶ Run training steps in a loop until stopping criterion is reached.
Parameters: save_fct ( Callable) – function to be invoked to save a model at dev checkpointsReturn type: None
-
backward(loss, dynet_profiling)[source]¶ Perform backward pass to accumulate gradients.
Parameters: - loss (
Expression) – Result of self.training_step(…) - dynet_profiling (
Integral) – if > 0, print the computation graph
Return type: None- loss (
-
update(trainer)[source]¶ Update DyNet weights using the given optimizer.
Parameters: trainer ( XnmtOptimizer) – DyNet trainerReturn type: None
-
-
class
xnmt.train.regimens.SimpleTrainingRegimen(model=Ref(path=model), src_file=None, trg_file=None, dev_every=0, dev_zero=False, batcher=bare(SrcBatcher{'batch_size': 32}), loss_calculator=bare(MLELoss), trainer=bare(SimpleSGDTrainer{'e0': 0.1}), run_for_epochs=None, lr_decay=1.0, lr_decay_times=3, patience=1, initial_patience=None, dev_tasks=None, dev_combinator=None, restart_trainer=False, reload_command=None, name='{EXP}', sample_train_sents=None, max_num_train_sents=None, max_src_len=None, max_trg_len=None, loss_comb_method=Ref(path=exp_global.loss_comb_method, default=sum), update_every=1, commandline_args=Ref(path=exp_global.commandline_args, default={}))[source]¶ Bases:
xnmt.train.tasks.SimpleTrainingTask,xnmt.train.regimens.TrainingRegimen,xnmt.persistence.SerializableParameters: - model (
ConditionedModel) – the model - src_file (
Union[None,str,Sequence[str]]) – the source training file - trg_file (
Optional[str]) – the target training file - dev_every (
Integral) – dev checkpoints every n sentences (0 for only after epoch) - dev_zero (
bool) – if True, add a checkpoint before training loop is entered (useful with pretrained models). - batcher (
Batcher) – Type of batcher - loss_calculator (
LossCalculator) – The method for calculating the loss. - trainer (
XnmtOptimizer) – Trainer object, default is SGD with learning rate 0.1 - run_for_epochs (
Optional[Integral]) – - lr_decay (
Real) – - lr_decay_times (
Integral) – Early stopping after decaying learning rate a certain number of times - patience (
Integral) – apply LR decay after dev scores haven’t improved over this many checkpoints - initial_patience (
Optional[Integral]) – if given, allows adjusting patience for the first LR decay - dev_tasks (
Optional[Sequence[EvalTask]]) – A list of tasks to use during the development stage. - dev_combinator (
Optional[str]) – A formula to combine together development scores into a single score to choose whether to perform learning rate decay, etc. e.g. ‘x[0]-x[1]’ would say that the first dev task score minus the second dev task score is our measure of how well we’re doing. If not specified, only the score from the first dev task will be used. - restart_trainer (
bool) – Restart trainer (useful for Adam) and revert weights to best dev checkpoint when applying LR decay (https://arxiv.org/pdf/1706.09733.pdf) - reload_command (
Optional[str]) – Command to change the input data after each epoch. –epoch EPOCH_NUM will be appended to the command. To just reload the data after each epoch set the command toTrue. - name (
str) – will be prepended to log outputs if given - sample_train_sents (
Optional[Integral]) – - max_num_train_sents (
Optional[Integral]) – - max_src_len (
Optional[Integral]) – - max_trg_len (
Optional[Integral]) – - loss_comb_method (
str) – method for combining loss across batch elements (sumoravg). - update_every (
Integral) – simulate large-batch training by accumulating gradients over several steps before updating parameters - commandline_args (
dict) –
-
run_training(save_fct)[source]¶ Main training loop (overwrites TrainingRegimen.run_training())
Return type: None
-
update(trainer)[source]¶ Update DyNet weights using the given optimizer.
Parameters: trainer ( XnmtOptimizer) – DyNet trainerReturn type: None
- model (
-
class
xnmt.train.regimens.AutobatchTrainingRegimen(model=Ref(path=model), src_file=None, trg_file=None, dev_every=0, dev_zero=False, batcher=bare(SrcBatcher{'batch_size': 32}), loss_calculator=bare(MLELoss), trainer=bare(SimpleSGDTrainer{'e0': 0.1}), run_for_epochs=None, lr_decay=1.0, lr_decay_times=3, patience=1, initial_patience=None, dev_tasks=None, dev_combinator=None, restart_trainer=False, reload_command=None, name='{EXP}', sample_train_sents=None, max_num_train_sents=None, max_src_len=None, max_trg_len=None, loss_comb_method=Ref(path=exp_global.loss_comb_method, default=sum), update_every=1, commandline_args=Ref(path=exp_global.commandline_args, default={}))[source]¶ Bases:
xnmt.train.regimens.SimpleTrainingRegimenThis regimen overrides SimpleTrainingRegimen by accumulating (summing) losses into a FactoreLossExpr before running forward/backward in the computation graph. It is designed to work with DyNet autobatching and when parts of architecture make batching difficult (such as structured encoders like TreeLSTMS or Graph Networks). The actual batch size is set through the “update_every” parameter, while the underlying Batcher is expected to have “batch_size” equal to 1.
Parameters: - model (
ConditionedModel) – the model - src_file (
Union[None,str,Sequence[str]]) – the source training file - trg_file (
Optional[str]) – the target training file - dev_every (
Integral) – dev checkpoints every n sentences (0 for only after epoch) - dev_zero (
bool) – if True, add a checkpoint before training loop is entered (useful with pretrained models). - batcher (
Batcher) – Type of batcher - loss_calculator (
LossCalculator) – The method for calculating the loss. - trainer (
XnmtOptimizer) – Trainer object, default is SGD with learning rate 0.1 - run_for_epochs (
Optional[Integral]) – - lr_decay (
Real) – - lr_decay_times (
Integral) – Early stopping after decaying learning rate a certain number of times - patience (
Integral) – apply LR decay after dev scores haven’t improved over this many checkpoints - initial_patience (
Optional[Integral]) – if given, allows adjusting patience for the first LR decay - dev_tasks (
Optional[Sequence[EvalTask]]) – A list of tasks to use during the development stage. - dev_combinator (
Optional[str]) – A formula to combine together development scores into a single score to choose whether to perform learning rate decay, etc. e.g. ‘x[0]-x[1]’ would say that the first dev task score minus the second dev task score is our measure of how good we’re doing. If not specified, only the score from the first dev task will be used. - restart_trainer (
bool) – Restart trainer (useful for Adam) and revert weights to best dev checkpoint when applying LR decay (https://arxiv.org/pdf/1706.09733.pdf) - reload_command (
Optional[str]) – Command to change the input data after each epoch. –epoch EPOCH_NUM will be appended to the command. To just reload the data after each epoch set the command toTrue. - name (
str) – will be prepended to log outputs if given - sample_train_sents (
Optional[Integral]) – - max_num_train_sents (
Optional[Integral]) – - max_src_len (
Optional[Integral]) – - max_trg_len (
Optional[Integral]) – - loss_comb_method (
str) – method for combining loss across batch elements (sumoravg). - update_every (
Integral) – how many instances to accumulate before updating parameters. This effectively sets the batch size under DyNet autobatching. - commandline_args (
dict) –
- model (
-
class
xnmt.train.regimens.MultiTaskTrainingRegimen(tasks, trainer=bare(SimpleSGDTrainer{'e0': 0.1}), dev_zero=False, update_every=1, commandline_args=Ref(path=exp_global.commandline_args, default=None))[source]¶ Bases:
xnmt.train.regimens.TrainingRegimenBase class for multi-task training classes. Mainly initializes tasks, performs sanity-checks, and manages set_train events.
Parameters: - tasks (
Sequence[TrainingTask]) – list of training tasks. The first item takes on the role of the main task, meaning it will control early stopping, learning rate schedule, and model checkpoints. - trainer (
XnmtOptimizer) – Trainer object, default is SGD with learning rate 0.1 - dev_zero (
bool) – if True, add a checkpoint before training loop is entered (useful with pretrained models). - update_every (
Integral) – simulate large-batch training by accumulating gradients over several steps before updating parameters - commandline_args (
dict) –
-
trigger_train_event(value)[source]¶ Trigger set_train event, but only if that would lead to a change of the value of set_train. :type value:
bool:param value: True or FalseReturn type: None
-
update(trainer)[source]¶ Update DyNet weights using the given optimizer.
Parameters: trainer ( XnmtOptimizer) – DyNet trainerReturn type: None
- tasks (
-
class
xnmt.train.regimens.SameBatchMultiTaskTrainingRegimen(tasks, trainer=bare(SimpleSGDTrainer{'e0': 0.1}), dev_zero=False, per_task_backward=True, loss_comb_method=Ref(path=exp_global.loss_comb_method, default=sum), update_every=1, n_task_steps=None, commandline_args=Ref(path=exp_global.commandline_args, default=None))[source]¶ Bases:
xnmt.train.regimens.MultiTaskTrainingRegimen,xnmt.persistence.SerializableMulti-task training where gradients are accumulated and weight updates are thus performed jointly for each task. The relative weight between tasks can be configured setting the number of steps to accumulate over for each task. Note that the batch size for each task also has an influence on task weighting. The stopping criterion of the first task is used (other tasks’ stopping criteria are ignored).
Parameters: - tasks (
Sequence[TrainingTask]) – Training tasks - trainer (
XnmtOptimizer) – The trainer is shared across tasks - dev_zero (
bool) – IfTrue, add a checkpoint before training loop is entered (useful with pretrained models). - per_task_backward (
bool) – IfTrue, call backward() for each task separately and renew computation graph between tasks. Yields the same results, butTrueuses less memory whileFalsemay be faster when using autobatching. - loss_comb_method (
str) – Method for combining loss across batch elements (‘sum’ or ‘avg’). - update_every (
Integral) – Simulate large-batch training by accumulating gradients over several steps before updating parameters. This is implemented as an outer loop, i.e. we first accumulate gradients from steps for each task, and then loop according to this parameter so that we collect multiple steps for each task and always according to the same ratio. - n_task_steps (
Optional[Sequence[Integral]]) – The number steps to accumulate for each task, useful for weighting tasks. - commandline_args (
dict) –
- tasks (
-
class
xnmt.train.regimens.AlternatingBatchMultiTaskTrainingRegimen(tasks, task_weights=None, trainer=bare(SimpleSGDTrainer{'e0': 0.1}), dev_zero=False, loss_comb_method=Ref(path=exp_global.loss_comb_method, default=sum), update_every_within=1, update_every_across=1, commandline_args=Ref(path=exp_global.commandline_args, default=None))[source]¶ Bases:
xnmt.train.regimens.MultiTaskTrainingRegimen,xnmt.persistence.SerializableMulti-task training where training steps are performed one after another.
The relative weight between tasks are explicitly specified explicitly, and for each step one task is drawn at random accordingly. The stopping criterion of the first task is used (other tasks’ stopping criteria are ignored).
Parameters: - tasks (
Sequence[TrainingTask]) – training tasks - trainer (
XnmtOptimizer) – the trainer is shared across tasks - dev_zero (
bool) – if True, add a checkpoint before training loop is entered (useful with pretrained models). - loss_comb_method (
str) – method for combining loss across batch elements (‘sum’ or ‘avg’). - update_every_within (
Integral) – Simulate large-batch training by accumulating gradients over several steps before updating parameters. The behavior here is to draw multiple times from the same task until update is invoked. - update_every_across (
Integral) – Simulate large-batch training by accumulating gradients over several steps before updating parameters. The behavior here is to draw tasks randomly several times before doing parameter updates. - commandline_args –
- tasks (
-
class
xnmt.train.regimens.SerialMultiTaskTrainingRegimen(tasks, trainer=bare(SimpleSGDTrainer{'e0': 0.1}), dev_zero=False, loss_comb_method=Ref(path=exp_global.loss_comb_method, default=sum), update_every=1, commandline_args=Ref(path=exp_global.commandline_args, default=None))[source]¶ Bases:
xnmt.train.regimens.MultiTaskTrainingRegimen,xnmt.persistence.SerializableTrains only first task until stopping criterion met, then the same for the second task, etc.
Useful to realize a pretraining-finetuning strategy.
Parameters: - tasks (
Sequence[TrainingTask]) – training tasks. The currently active task is treated as main task. - trainer (
XnmtOptimizer) – the trainer is shared across tasks - dev_zero (
bool) – if True, add a checkpoint before training loop is entered (useful with pretrained models). - loss_comb_method (
str) – method for combining loss across batch elements (‘sum’ or ‘avg’). - update_every (
Integral) – simulate large-batch training by accumulating gradients over several steps before updating parameters - commandline_args (
dict) –
- tasks (
TrainingTask¶
-
class
xnmt.train.tasks.TrainingTask(model)[source]¶ Bases:
objectBase class for a training task. Training tasks can perform training steps and keep track of the training state, but may not implement the actual training loop.
Parameters: model ( TrainableModel) – The model to train-
should_stop_training()[source]¶ Returns: True iff training is finished, i.e. training_step(…) should not be called again
-
training_step(**kwargs)[source]¶ Perform forward pass for the next training step and handle training logic (switching epoch, reshuffling, ..)
Parameters: **kwargs – depends on subclass implementations Return type: FactoredLossExprReturns: Loss
-
next_minibatch()[source]¶ Infinitely loop over training minibatches.
Return type: Iterator[+T_co]Returns: Generator yielding (src_batch,trg_batch) tuples
-
checkpoint(control_learning_schedule=False)[source]¶ Perform a dev checkpoint.
Parameters: control_learning_schedule ( bool) – IfFalse, only evaluate dev data. IfTrue, also perform model saving, LR decay etc. if needed.Return type: boolReturns: Trueiff the model needs saving
-
-
class
xnmt.train.tasks.SimpleTrainingTask(model, src_file=None, trg_file=None, dev_every=0, batcher=bare(SrcBatcher{'batch_size': 32}), loss_calculator=bare(MLELoss), run_for_epochs=None, lr_decay=1.0, lr_decay_times=3, patience=1, initial_patience=None, dev_tasks=None, dev_combinator=None, restart_trainer=False, reload_command=None, name=None, sample_train_sents=None, max_num_train_sents=None, max_src_len=None, max_trg_len=None)[source]¶ Bases:
xnmt.train.tasks.TrainingTask,xnmt.persistence.SerializableParameters: - model (
ConditionedModel) – a trainable supervised model - src_file (
Union[str,Sequence[str],None]) – The file for the source data. - trg_file (
Optional[str]) – The file for the target data. - dev_every (
Integral) – dev checkpoints every n sentences (0 for only after epoch) - batcher (
Batcher) – Type of batcher - loss_calculator (
LossCalculator) – - run_for_epochs (
Optional[Integral]) – number of epochs (None for unlimited epochs) - lr_decay (
Real) – decay learning rate by multiplying by this factor - lr_decay_times (
Integral) – Early stopping after decaying learning rate a certain number of times - patience (
Integral) – apply LR decay after dev scores haven’t improved over this many checkpoints - initial_patience (
Optional[Integral]) – if given, allows adjusting patience for the first LR decay - dev_tasks (
Optional[Sequence[EvalTask]]) – A list of tasks to run on the development set - dev_combinator – A formula to combine together development scores into a single score to choose whether to perform learning rate decay, etc. e.g. ‘x[0]-x[1]’ would say that the first dev task score minus the second dev task score is our measure of how good we’re doing. If not specified, only the score from the first dev task will be used.
- restart_trainer (
bool) – Restart trainer (useful for Adam) and revert weights to best dev checkpoint when applying LR decay (https://arxiv.org/pdf/1706.09733.pdf) - reload_command (
Optional[str]) – Command to change the input data after each epoch. –epoch EPOCH_NUM will be appended to the command. To just reload the data after each epoch set the command to ‘true’. - sample_train_sents (
Optional[Integral]) – If given, load a random subset of training sentences before each epoch. Useful when training data does not fit in memory. - max_num_train_sents (
Optional[Integral]) – Train only on the first n sentences - max_src_len (
Optional[Integral]) – Discard training sentences with source-side longer than this - max_trg_len (
Optional[Integral]) – Discard training sentences with target-side longer than this - name (
Optional[str]) – will be prepended to log outputs if given
-
should_stop_training()[source]¶ Signal stopping if self.early_stopping_reached is marked or we exhausted the number of requested epochs.
Return type: bool
-
cur_num_minibatches()[source]¶ Current number of minibatches (may change between epochs, e.g. for randomizing batchers or if reload_command is given)
Return type: Integral
-
cur_num_sentences()[source]¶ Current number of parallel sentences (may change between epochs, e.g. if reload_command is given)
Return type: Integral
-
next_minibatch()[source]¶ Infinitely loops over training minibatches and advances internal epoch state after every complete sweep over the corpus.
Return type: Iterator[+T_co]Returns: Generator yielding (src_batch,trg_batch) tuples
- model (
Parameters¶
ParamManager¶
-
class
xnmt.param_collections.ParamManager[source]¶ Bases:
objectA static class that manages the currently loaded DyNet parameters of all components.
Responsibilities are registering of all components that use DyNet parameters and loading pretrained parameters. Components can register parameters by calling ParamManager.my_params(self) from within their __init__() method. This allocates a subcollection with a unique identifier for this component. When loading previously saved parameters, one or several paths are specified to look for the corresponding saved DyNet collection named after this identifier.
-
static
init_param_col()[source]¶ Initializes or resets the parameter collection.
This must be invoked before every time a new model is loaded (e.g. on startup and between consecutive experiments).
Return type: None
-
static
add_load_path(data_file)[source]¶ Add new data directory path to load from.
When calling populate(), pretrained parameters from all directories added in this way are searched for the requested component identifiers.
Parameters: data_file ( str) – a data directory (usually named*.data) containing DyNet parameter collections.Return type: None
-
static
populate()[source]¶ Populate the parameter collections.
Searches the given data paths and loads parameter collections if they exist, otherwise leave parameters in their randomly initialized state.
Return type: None
-
static
my_params(subcol_owner)[source]¶ Creates a dedicated parameter subcollection for a serializable object.
This should only be called from the __init__ method of a Serializable.
Parameters: subcol_owner (Serializable) – The object which is requesting to be assigned a subcollection. Return type: ParameterCollectionReturns: The assigned subcollection.
-
static
Optimizer¶
-
class
xnmt.optimizers.XnmtOptimizer(optimizer, skip_noisy=False)[source]¶ Bases:
objectA base classe for trainers. Trainers are mostly simple wrappers of DyNet trainers but can add extra functionality.
Parameters: - optimizer (
Trainer) – the underlying DyNet optimizer (trainer) - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
-
status()[source]¶ Outputs information about the trainer in the stderr.
(number of updates since last call, number of clipped gradients, learning rate, etc…)
Return type: None
-
set_clip_threshold(thr)[source]¶ Set clipping thershold
To deactivate clipping, set the threshold to be <=0
Parameters: thr ( Real) – Clipping thresholdReturn type: None
- optimizer (
-
class
xnmt.optimizers.SimpleSGDTrainer(e0=0.1, skip_noisy=False)[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableStochastic gradient descent trainer
This trainer performs stochastic gradient descent, the goto optimization procedure for neural networks.
Parameters: - e0 (
Real) – Initial learning rate - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
- e0 (
-
class
xnmt.optimizers.MomentumSGDTrainer(e0=0.01, mom=0.9, skip_noisy=False)[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableStochastic gradient descent with momentum
This is a modified version of the SGD algorithm with momentum to stablize the gradient trajectory.
Parameters: - e0 (
Real) – Initial learning rate - mom (
Real) – Momentum - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
- e0 (
-
class
xnmt.optimizers.AdagradTrainer(e0=0.1, eps=1e-20, skip_noisy=False)[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableAdagrad optimizer
The adagrad algorithm assigns a different learning rate to each parameter.
Parameters: - e0 (
Real) – Initial learning rate - eps (
Real) – Epsilon parameter to prevent numerical instability - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
- e0 (
-
class
xnmt.optimizers.AdadeltaTrainer(eps=1e-06, rho=0.95, skip_noisy=False)[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableAdaDelta optimizer
The AdaDelta optimizer is a variant of Adagrad aiming to prevent vanishing learning rates.
Parameters: - eps (
Real) – Epsilon parameter to prevent numerical instability - rho (
Real) – Update parameter for the moving average of updates in the numerator - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
- eps (
-
class
xnmt.optimizers.AdamTrainer(alpha=0.001, beta_1=0.9, beta_2=0.999, eps=1e-08, skip_noisy=False)[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableAdam optimizer
The Adam optimizer is similar to RMSProp but uses unbiased estimates of the first and second moments of the gradient
Parameters: - alpha (
Real) – Initial learning rate - beta_1 (
Real) – Moving average parameter for the mean - beta_2 (
Real) – Moving average parameter for the variance - eps (
Real) – Epsilon parameter to prevent numerical instability - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
- alpha (
-
class
xnmt.optimizers.NoamTrainer(alpha=1.0, dim=512, warmup_steps=4000, beta_1=0.9, beta_2=0.98, eps=1e-09, skip_noisy=False)[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableProposed in the paper “Attention is all you need” (https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf) [Page 7, Eq. 3] In this the learning rate of Adam Optimizer is increased for the first warmup steps followed by a gradual decay
Parameters: - alpha (
Real) – - dim (
Integral) – - warmup_steps (
Optional[Integral]) – - beta_1 (
Real) – - beta_2 (
Real) – - eps (
Real) – - skip_noisy (
bool) – keep track of a moving average and a moving standard deviation of the log of the gradient norm values, and abort a step if the norm of the gradient exceeds four standard deviations of the moving average. Reference: https://arxiv.org/pdf/1804.09849.pdf
- alpha (
-
class
xnmt.optimizers.DummyTrainer[source]¶ Bases:
xnmt.optimizers.XnmtOptimizer,xnmt.persistence.SerializableA dummy trainer that does not perform any parameter updates.
-
status()[source]¶ Outputs information about the trainer in the stderr.
(number of updates since last call, number of clipped gradients, learning rate, etc…)
Return type: None
-
set_clip_threshold(thr)[source]¶ Set clipping thershold
To deactivate clipping, set the threshold to be <=0
Parameters: thr – Clipping threshold Return type: None
-
ParamInitializer¶
-
class
xnmt.param_initializers.ParamInitializer[source]¶ Bases:
objectA parameter initializer that delegates to the DyNet initializers and possibly performs some extra configuration.
-
class
xnmt.param_initializers.NormalInitializer(mean=0, var=1)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableWraps DyNet’s NormalInitializer: http://dynet.readthedocs.io/en/latest/python_ref.html#dynet.NormalInitializer
Initialize the parameters with a gaussian distribution.
Parameters: - mean (
Real) – Mean of the distribution - var (
Real) – Variance of the distribution
-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: NormalInitializerReturns: a dynet initializer object
- dim (
- mean (
-
class
xnmt.param_initializers.UniformInitializer(scale)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableWraps DyNet’s UniformInitializer: http://dynet.readthedocs.io/en/latest/python_ref.html#dynet.UniformInitializer
Initialize the parameters with a uniform distribution. :type scale:
Real:param scale: Parameters are sampled from![\mathcal U([-\texttt{scale},\texttt{scale}])](_images/math/53e703b359ec6d8f689d28d3275ad9cf8536ce7b.png)
-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: UniformInitializerReturns: a dynet initializer object
- dim (
-
-
class
xnmt.param_initializers.ConstInitializer(c)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableWraps DyNet’s ConstInitializer: http://dynet.readthedocs.io/en/latest/python_ref.html#dynet.ConstInitializer
Initialize the parameters with a constant value.
Parameters: c ( Real) – Value to initialize the parameters-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: ConstInitializerReturns: a dynet initializer object
- dim (
-
-
class
xnmt.param_initializers.GlorotInitializer(gain=1.0)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableWraps DyNet’s GlorotInitializer: http://dynet.readthedocs.io/en/latest/python_ref.html#dynet.GlorotInitializer
Initializes the weights according to Glorot & Bengio (2011)
If the dimensions of the parameter matrix are
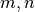 , the weights are sampled from
, the weights are sampled from ![\mathcal U([-g\sqrt{\frac{6}{m+n}},g\sqrt{\frac{6}{m+n}}])](_images/math/5acb30c136bc9b68d253acdf2782c7cff8b9814e.png)
The gain
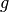 depends on the activation function :
depends on the activation function : : 1.0
: 1.0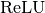 : 0.5
: 0.5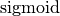 : 4.0
: 4.0- Any smooth function
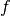 :
: 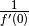
In addition to the DyNet class, this also supports the case where one parameter object stores several matrices (as is popular for computing LSTM gates, for instance).
Note: This is also known as Xavier initializationParameters: gain ( Real) – Gain (Depends on the activation function)-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimensions of parameter tensor - is_lookup (
bool) – Whether the parameter is a lookup parameter - num_shared (
Integral) – If > 1, treat the first dimension as spanning multiple matrices, each of which is initialized individually
Return type: UniformInitializerReturns: a dynet initializer object
- dim (
-
class
xnmt.param_initializers.FromFileInitializer(fname)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableWraps DyNet’s FromFileInitializer: http://dynet.readthedocs.io/en/latest/python_ref.html#dynet.FromFileInitializer
Initialize parameter from file.
Parameters: fname ( str) – File name-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: FromFileInitializerReturns: a dynet initializer object
- dim (
-
-
class
xnmt.param_initializers.NumpyInitializer(array)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableWraps DyNet’s NumpyInitializer: http://dynet.readthedocs.io/en/latest/python_ref.html#dynet.NumpyInitializer
Initialize from numpy array
Alternatively, use
ParameterCollection.parameters_from_numpy()Parameters: array ( ndarray) – Numpy array-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: NumpyInitializerReturns: a dynet initializer object
- dim (
-
-
class
xnmt.param_initializers.ZeroInitializer[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableInitializes parameter matrix to zero (most appropriate for bias parameters).
-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: ConstInitializerReturns: a dynet initializer object
- dim (
-
-
class
xnmt.param_initializers.LeCunUniformInitializer(scale=1.0)[source]¶ Bases:
xnmt.param_initializers.ParamInitializer,xnmt.persistence.SerializableReference: LeCun 98, Efficient Backprop http://yann.lecun.com/exdb/publis/pdf/lecun-98b.pdf
Parameters: scale ( Real) – scale-
initializer(dim, is_lookup=False, num_shared=1)[source]¶ Parameters: - dim (
Tuple[Integral]) – dimension of parameter tensor - is_lookup (
bool) – True if parameters are a lookup matrix - num_shared (
Integral) – Indicates if one parameter object holds multiple matrices
Return type: UniformInitializerReturns: a dynet initializer object
- dim (
-
Inference¶
AutoRegressiveInference¶
-
class
xnmt.inferences.Inference(src_file=None, trg_file=None, ref_file=None, max_src_len=None, max_num_sents=None, mode='onebest', batcher=bare(InOrderBatcher{'batch_size': 1}), reporter=None)[source]¶ Bases:
objectA template class for classes that perform inference.
Parameters: - src_file (
Optional[str]) – path of input src file to be translated - trg_file (
Optional[str]) – path of file where trg translatons will be written - ref_file (
Optional[str]) – path of file with reference translations, e.g. for forced decoding - max_src_len (
Optional[int]) – Remove sentences from data to decode that are longer than this on the source side - max_num_sents (
Optional[int]) – Stop decoding after the first n sentences. - mode (
str) –type of decoding to perform.
onebest: generate one best.score: output scores, useful for rescoringforced: perform forced decoding.forceddebug: perform forced decoding, calculate training loss, and make sure the scores are identical for debugging purposes.
- batcher (
InOrderBatcher) – inference batcher, needed e.g. in connection withpad_src_token_to_multiple - reporter (
Union[None,Reporter,Sequence[Reporter]]) – a reporter to create reports for each decoded sentence
-
perform_inference(generator, src_file=None, trg_file=None, ref_file=None)[source]¶ Perform inference.
Parameters: - generator (
GeneratorModel) – the model to be used - src_file (
Optional[str]) – path of input src file to be translated - trg_file (
Optional[str]) – path of file where trg translatons will be written
Return type: None- generator (
- src_file (
-
class
xnmt.inferences.IndependentOutputInference(src_file=None, trg_file=None, ref_file=None, max_src_len=None, max_num_sents=None, post_process=None, mode='onebest', batcher=bare(InOrderBatcher{'batch_size': 1}), reporter=None)[source]¶ Bases:
xnmt.inferences.Inference,xnmt.persistence.SerializableInference when outputs are produced independently, including for classifiers that produce only a single output.
Assumes that generator.generate() takes arguments src, idx
Parameters: - src_file (
Optional[str]) – path of input src file to be translated - trg_file (
Optional[str]) – path of file where trg translatons will be written - ref_file (
Optional[str]) – path of file with reference translations, e.g. for forced decoding - max_src_len (
Optional[int]) – Remove sentences from data to decode that are longer than this on the source side - max_num_sents (
Optional[int]) – Stop decoding after the first n sentences. - post_process (
Union[None,str,OutputProcessor,Sequence[OutputProcessor]]) – post-processing of translation outputs (available string shortcuts:none,join-char,join-bpe,join-piece) - mode (
str) –type of decoding to perform.
onebest: generate one best.score: output scores, useful for rescoring
- batcher (
InOrderBatcher) – inference batcher, needed e.g. in connection withpad_src_token_to_multiple - reporter (
Union[None,Reporter,Sequence[Reporter]]) – a reporter to create reports for each decoded sentence
- src_file (
-
class
xnmt.inferences.AutoRegressiveInference(src_file=None, trg_file=None, ref_file=None, max_src_len=None, max_num_sents=None, post_process=[], search_strategy=bare(BeamSearch), mode='onebest', batcher=bare(InOrderBatcher{'batch_size': 1}), reporter=None)[source]¶ Bases:
xnmt.inferences.Inference,xnmt.persistence.SerializablePerforms inference for auto-regressive models that expand based on their own previous outputs.
Assumes that generator.generate() takes arguments src, idx, search_strategy, forced_trg_ids
Parameters: - src_file (
Optional[str]) – path of input src file to be translated - trg_file (
Optional[str]) – path of file where trg translatons will be written - ref_file (
Optional[str]) – path of file with reference translations, e.g. for forced decoding - max_src_len (
Optional[int]) – Remove sentences from data to decode that are longer than this on the source side - max_num_sents (
Optional[int]) – Stop decoding after the first n sentences. - post_process (
Union[str,OutputProcessor,Sequence[OutputProcessor]]) – post-processing of translation outputs (available string shortcuts:none,``join-char``,``join-bpe``,``join-piece``) - search_strategy (
SearchStrategy) – a search strategy used during decoding. - mode (
str) –type of decoding to perform.
onebest: generate one best.score: output scores, useful for rescoring
- batcher (
InOrderBatcher) – inference batcher, needed e.g. in connection withpad_src_token_to_multiple - reporter (
Union[None,Reporter,Sequence[Reporter]]) – a reporter to create reports for each decoded sentence
- src_file (
-
class
xnmt.inferences.CascadeInference(steps)[source]¶ Bases:
xnmt.inferences.Inference,xnmt.persistence.SerializableInference class that performs inference as a series of independent inference steps.
Steps are performed using a list of inference sub-objects and a list of models. Intermediate outputs are written out to disk and then read by the next time step.
The generator passed to
perform_inferencemust be axnmt.models.CascadeGenerator.Parameters: steps ( Sequence[Inference]) – list of inference objects-
perform_inference(generator, src_file=None, trg_file=None, ref_file=None)[source]¶ Perform inference.
Parameters: - generator (
CascadeGenerator) – the model to be used - src_file (
Optional[str]) – path of input src file to be translated - trg_file (
Optional[str]) – path of file where trg translatons will be written
Return type: None- generator (
-
SearchStrategy¶
-
class
xnmt.search_strategies.SearchOutput(word_ids, attentions, score, state, mask)¶ Bases:
tupleOutput of the search words_ids: list of generated word ids attentions: list of corresponding attention vector of word_ids score: a single value of log(p(E|F)) logsoftmaxes: a corresponding softmax vector of the score. score = logsoftmax[word_id] state: a NON-BACKPROPAGATEABLE state that is used to produce the logsoftmax layer
state is usually used to generate ‘baseline’ in reinforce lossmasks: whether the particular word id should be ignored or not (1 for not, 0 for yes)
-
attentions¶ Alias for field number 1
-
mask¶ Alias for field number 4
-
score¶ Alias for field number 2
-
state¶ Alias for field number 3
-
word_ids¶ Alias for field number 0
-
-
class
xnmt.search_strategies.SearchStrategy[source]¶ Bases:
objectA template class to generate translation from the output probability model. (Non-batched operation)
-
generate_output(translator, initial_state, src_length=None)[source]¶ Parameters: - translator (xnmt.models.translators.AutoRegressiveTranslator) – a translator
- initial_state (
AutoRegressiveDecoderState) – initial decoder state - src_length (
Optional[Integral]) – length of src sequence, required for some types of length normalization
Return type: List[SearchOutput]Returns: List of (word_ids, attentions, score, logsoftmaxes)
-
-
class
xnmt.search_strategies.GreedySearch(max_len=100)[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.search_strategies.SearchStrategyPerforms greedy search (aka beam search with beam size 1)
Parameters: max_len ( Integral) – maximum number of tokens to generate.-
generate_output(translator, initial_state, src_length=None)[source]¶ Parameters: - translator (xnmt.models.translators.AutoRegressiveTranslator) – a translator
- initial_state (
AutoRegressiveDecoderState) – initial decoder state - src_length (
Optional[Integral]) – length of src sequence, required for some types of length normalization
Return type: List[SearchOutput]Returns: List of (word_ids, attentions, score, logsoftmaxes)
-
-
class
xnmt.search_strategies.BeamSearch(beam_size=1, max_len=100, len_norm=bare(NoNormalization), one_best=True, scores_proc=None)[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.search_strategies.SearchStrategyPerforms beam search.
Parameters: - beam_size (
Integral) – number of beams - max_len (
Integral) – maximum number of tokens to generate. - len_norm (
LengthNormalization) – type of length normalization to apply - one_best (
bool) – Whether to output the best hyp only or all completed hyps. - scores_proc (
Optional[Callable[[ndarray],None]]) – apply an optional operation on all scores prior to choosing the top k. E.g. use withxnmt.length_normalization.EosBooster.
-
class
Hypothesis(score, output, parent, word)¶ Bases:
tuple-
output¶ Alias for field number 1
-
parent¶ Alias for field number 2
-
score¶ Alias for field number 0
-
word¶ Alias for field number 3
-
-
generate_output(translator, initial_state, src_length=None)[source]¶ Parameters: - translator (xnmt.models.translators.AutoRegressiveTranslator) – a translator
- initial_state (
AutoRegressiveDecoderState) – initial decoder state - src_length (
Optional[Integral]) – length of src sequence, required for some types of length normalization
Return type: List[SearchOutput]Returns: List of (word_ids, attentions, score, logsoftmaxes)
- beam_size (
-
class
xnmt.search_strategies.SamplingSearch(max_len=100, sample_size=5)[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.search_strategies.SearchStrategyPerforms search based on the softmax probability distribution. Similar to greedy searchol
Parameters: - max_len (
Integral) – - sample_size (
Integral) –
-
generate_output(translator, initial_state, src_length=None)[source]¶ Parameters: - translator (xnmt.models.translators.AutoRegressiveTranslator) – a translator
- initial_state (
AutoRegressiveDecoderState) – initial decoder state - src_length (
Optional[Integral]) – length of src sequence, required for some types of length normalization
Return type: List[SearchOutput]Returns: List of (word_ids, attentions, score, logsoftmaxes)
- max_len (
-
class
xnmt.search_strategies.MctsSearch(visits=200, max_len=100)[source]¶ Bases:
xnmt.persistence.Serializable,xnmt.search_strategies.SearchStrategyPerforms search with Monte Carlo Tree Search
-
generate_output(translator, dec_state, src_length=None)[source]¶ Parameters: - translator (xnmt.models.translators.AutoRegressiveTranslator) – a translator
- initial_state – initial decoder state
- src_length (
Optional[Integral]) – length of src sequence, required for some types of length normalization
Return type: List[SearchOutput]Returns: List of (word_ids, attentions, score, logsoftmaxes)
-
LengthNormalization¶
-
class
xnmt.length_norm.LengthNormalization[source]¶ Bases:
objectA template class to adjust scores for length normalization during search.
-
normalize_completed(completed_hyps, src_length=None)[source]¶ Apply normalization step to completed hypotheses after search and return the normalized scores.
Parameters: - completed_hyps (
Sequence[Hypothesis]) – list of completed Hypothesis objects, will be normalized in-place - src_length (
Optional[int]) – length of source sequence (None if not given)
Return type: Sequence[float]Returns: normalized scores
- completed_hyps (
-
normalize_partial_topk(score_so_far, score_to_add, new_len)[source]¶ Apply normalization step after expanding a partial hypothesis and selecting the top k scores.
Parameters: - score_so_far – log score of the partial hypothesis
- score_to_add – log score of the top-k item that is to be added
- new_len – new length of partial hypothesis with current word already appended
Returns: new score after applying score_to_add to score_so_far
-
-
class
xnmt.length_norm.NoNormalization[source]¶ Bases:
xnmt.length_norm.LengthNormalization,xnmt.persistence.SerializableAdding no form of length normalization.
-
normalize_completed(completed_hyps, src_length=None)[source]¶ Apply normalization step to completed hypotheses after search and return the normalized scores.
Parameters: - completed_hyps (
Sequence[Hypothesis]) – list of completed Hypothesis objects, will be normalized in-place - src_length (
Optional[int]) – length of source sequence (None if not given)
Return type: Sequence[float]Returns: normalized scores
- completed_hyps (
-
-
class
xnmt.length_norm.AdditiveNormalization(penalty=-0.1, apply_during_search=False)[source]¶ Bases:
xnmt.length_norm.LengthNormalization,xnmt.persistence.SerializableAdding a fixed word penalty everytime the word is added.
-
normalize_completed(completed_hyps, src_length=None)[source]¶ Apply normalization step to completed hypotheses after search and return the normalized scores.
Parameters: - completed_hyps (
Sequence[Hypothesis]) – list of completed Hypothesis objects, will be normalized in-place - src_length (
Optional[int]) – length of source sequence (None if not given)
Return type: Sequence[float]Returns: normalized scores
- completed_hyps (
-
normalize_partial_topk(score_so_far, score_to_add, new_len)[source]¶ Apply normalization step after expanding a partial hypothesis and selecting the top k scores.
Parameters: - score_so_far – log score of the partial hypothesis
- score_to_add – log score of the top-k item that is to be added
- new_len – new length of partial hypothesis with current word already appended
Returns: new score after applying score_to_add to score_so_far
-
-
class
xnmt.length_norm.PolynomialNormalization(m=1, apply_during_search=False)[source]¶ Bases:
xnmt.length_norm.LengthNormalization,xnmt.persistence.SerializableDividing by the length (raised to some power)
-
normalize_completed(completed_hyps, src_length=None)[source]¶ Apply normalization step to completed hypotheses after search and return the normalized scores.
Parameters: - completed_hyps (
Sequence[Hypothesis]) – list of completed Hypothesis objects, will be normalized in-place - src_length (
Optional[int]) – length of source sequence (None if not given)
Return type: Sequence[float]Returns: normalized scores
- completed_hyps (
-
normalize_partial_topk(score_so_far, score_to_add, new_len)[source]¶ Apply normalization step after expanding a partial hypothesis and selecting the top k scores.
Parameters: - score_so_far – log score of the partial hypothesis
- score_to_add – log score of the top-k item that is to be added
- new_len – new length of partial hypothesis with current word already appended
Returns: new score after applying score_to_add to score_so_far
-
-
class
xnmt.length_norm.MultinomialNormalization(sent_stats)[source]¶ Bases:
xnmt.length_norm.LengthNormalization,xnmt.persistence.SerializableThe algorithm followed by: Tree-to-Sequence Attentional Neural Machine Translation https://arxiv.org/pdf/1603.06075.pdf
-
class
xnmt.length_norm.GaussianNormalization(sent_stats)[source]¶ Bases:
xnmt.length_norm.LengthNormalization,xnmt.persistence.SerializableThe Gaussian regularization encourages the inference to select sents that have similar lengths as the sents in the training set. refer: https://arxiv.org/pdf/1509.04942.pdf
-
normalize_completed(completed_hyps, src_length=None)[source]¶ Apply normalization step to completed hypotheses after search and return the normalized scores.
Parameters: - completed_hyps (
Sequence[Hypothesis]) – list of completed Hypothesis objects, will be normalized in-place - src_length (
Optional[int]) – length of source sequence (None if not given)
Return type: Sequence[float]Returns: normalized scores
- completed_hyps (
-
-
class
xnmt.length_norm.EosBooster(boost_val)[source]¶ Bases:
xnmt.persistence.SerializableCallable that applies boosting of end-of-sequence token, can be used with
xnmt.search_strategy.BeamSearch.Parameters: boost_val ( Real) – value to add to the eos token’s log probability. Positive values make sentences shorter, negative values make sentences longer.
Evaluation¶
EvalTasks¶
-
class
xnmt.eval.tasks.EvalTask[source]¶ Bases:
objectAn EvalTask is a task that does evaluation and returns one or more EvalScore objects.
-
class
xnmt.eval.tasks.LossEvalTask(src_file, ref_file=None, model=Ref(path=model), batcher=Ref(path=train.batcher, default=SrcBatcher@140549180156224), loss_calculator=bare(MLELoss), max_src_len=None, max_trg_len=None, max_num_sents=None, loss_comb_method=Ref(path=exp_global.loss_comb_method, default=sum), desc=None)[source]¶ Bases:
xnmt.eval.tasks.EvalTask,xnmt.persistence.SerializableA task that does evaluation of the loss function.
Parameters: - src_file (
Union[str,Sequence[str]]) – source file name - ref_file (
Optional[str]) – reference file name - model (
GeneratorModel) – generator model to use for inference - batcher (
Batcher) – batcher to use - loss_calculator (
LossCalculator) – loss calculator - max_src_len (
Optional[int]) – omit sentences with source length greater than specified number - max_trg_len (
Optional[int]) – omit sentences with target length greater than specified number - max_num_sents (
Optional[int]) – compute loss only for the first n sentences in the given corpus - loss_comb_method (
str) – method for combining loss across batch elements (‘sum’ or ‘avg’). - desc (
Optional[Any]) – description to pass on to computed score objects
- src_file (
-
class
xnmt.eval.tasks.AccuracyEvalTask(src_file, ref_file, hyp_file, model=Ref(path=model), eval_metrics='bleu', inference=None, perform_inference=True, desc=None)[source]¶ Bases:
xnmt.eval.tasks.EvalTask,xnmt.persistence.SerializableA task that does evaluation of some measure of accuracy.
Parameters: - src_file (
Union[str,Sequence[str]]) – path(s) to read source file(s) from - ref_file (
Union[str,Sequence[str]]) – path(s) to read reference file(s) from - hyp_file (
str) – path to write hypothesis file to - model (
GeneratorModel) – generator model to generate hypothesis with - eval_metrics (
Union[str,Evaluator,Sequence[Evaluator]]) – list of evaluation metrics (list of Evaluator objects or string of comma-separated shortcuts) - inference (
Optional[Inference]) – inference object - perform_inference (
bool) – Whether to generate the output or not. One eval task can use an already existing hyp_file that was generated by the previous eval tasks. - desc (
Optional[Any]) – human-readable description passed on to resulting score objects
- src_file (
-
class
xnmt.eval.tasks.DecodingEvalTask(src_file, hyp_file, model=Ref(path=model), inference=None)[source]¶ Bases:
xnmt.eval.tasks.EvalTask,xnmt.persistence.SerializableA task that does performs decoding without comparing against a reference.
Parameters: - src_file (
Union[str,Sequence[str]]) – path(s) to read source file(s) from - hyp_file (
str) – path to write hypothesis file to - model (
GeneratorModel) – generator model to generate hypothesis with - inference (
Optional[Inference]) – inference object
- src_file (
Eval Metrics¶
This module contains classes to compute evaluation metrics and to hold the resulting scores.
EvalScore subclasses represent a computed score, including useful statistics, and can be
printed with an informative string representation.
Evaluator subclasses are used to compute these scores. Currently the following are implemented:
LossScore(created directly by the model)BLEUEvaluatorandFastBLEUEvaluatorcreateBLEUScoreobjectsGLEUEvaluatorcreatesGLEUScoreobjectsWEREvaluatorcreatesWERScoreobjectsCEREvaluatorcreatesCERScoreobjectsExternalEvaluatorcreatesExternalScoreobjectsSequenceAccuracyEvaluatorcreatesSequenceAccuracyScoreobjects
-
class
xnmt.eval.metrics.EvalScore(desc=None)[source]¶ Bases:
objectA template class for scores as resulting from using an
Evaluator.Parameters: desc ( Optional[Any]) – human-readable description to include in log outputs-
higher_is_better()[source]¶ Return
Trueif higher values are favorable,Falseotherwise.Return type: boolReturns: Whether higher values are favorable.
-
value()[source]¶ Get the numeric value of the evaluated metric.
Return type: floatReturns: Numeric evaluation score.
-
-
class
xnmt.eval.metrics.SentenceLevelEvalScore(desc=None)[source]¶ Bases:
xnmt.eval.metrics.EvalScoreA template class for scores that work on a sentence-level and can be aggregated to corpus-level.
-
static
aggregate(scores, desc=None)[source]¶ Aggregate a sequence of sentence-level scores into a corpus-level score.
Parameters: - scores (
Sequence[SentenceLevelEvalScore]) – list of sentence-level scores. - desc (
Optional[Any]) – human-readable description.
Return type: Returns: Score object that is the aggregate of all sentence-level scores.
- scores (
-
static
-
class
xnmt.eval.metrics.LossScore(loss, loss_stats=None, num_ref_words=None, desc=None)[source]¶ Bases:
xnmt.eval.metrics.EvalScore,xnmt.persistence.SerializableScore indicating the value of the loss function of a neural network.
Parameters: - loss (
Real) – the (primary) loss value - loss_stats (
Optional[Dict[str,Real]]) – info on additional loss values - num_ref_words (
Optional[Integral]) – number of reference tokens - desc (
Optional[Any]) – human-readable description to include in log outputs
- loss (
-
class
xnmt.eval.metrics.BLEUScore(bleu, frac_score_list=None, brevity_penalty_score=None, hyp_len=None, ref_len=None, ngram=4, desc=None)[source]¶ Bases:
xnmt.eval.metrics.EvalScore,xnmt.persistence.SerializableClass to keep a BLEU score.
Parameters: - bleu (
Real) – actual BLEU score between 0 and 1 - frac_score_list (
Optional[Sequence[Real]]) – list of fractional scores for each n-gram order - brevity_penalty_score (
Optional[Real]) – brevity penalty that was multiplied to the precision score. - hyp_len (
Optional[Integral]) – length of hypothesis - ref_len (
Optional[Integral]) – length of reference - ngram (
Integral) – match n-grams up to this order (usually 4) - desc (
Optional[Any]) – human-readable description to include in log outputs
- bleu (
-
class
xnmt.eval.metrics.GLEUScore(corpus_n_match, corpus_total, hyp_len, ref_len, desc=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvalScore,xnmt.persistence.SerializableClass to keep a GLEU (Google BLEU) score.
Parameters: - gleu – actual GLEU score between 0 and 1
- hyp_len (
Integral) – length of hypothesis - ref_len (
Integral) – length of reference - desc (
Optional[Any]) – human-readable description to include in log outputs
-
higher_is_better()[source]¶ Return
Trueif higher values are favorable,Falseotherwise.Returns: Whether higher values are favorable.
-
score_str()[source]¶ A string representation of the evaluated score, potentially including additional statistics.
Returns: String representation of score.
-
static
aggregate(scores, desc=None)[source]¶ Aggregate a sequence of sentence-level scores into a corpus-level score.
Parameters: - scores (
Sequence[SentenceLevelEvalScore]) – list of sentence-level scores. - desc (
Optional[Any]) – human-readable description.
Returns: Score object that is the aggregate of all sentence-level scores.
- scores (
-
class
xnmt.eval.metrics.LevenshteinScore(correct, substitutions, insertions, deletions, desc=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvalScoreA template class for Levenshtein-based scores.
Parameters: - correct (
Integral) – number of correct matches - substitutions (
Integral) – number of substitution errors - insertions (
Integral) – number of insertion errors - deletions (
Integral) – number of deletion errors - desc (
Optional[Any]) – human-readable description to include in log outputs
-
higher_is_better()[source]¶ Return
Trueif higher values are favorable,Falseotherwise.Returns: Whether higher values are favorable.
-
score_str()[source]¶ A string representation of the evaluated score, potentially including additional statistics.
Returns: String representation of score.
-
static
aggregate(scores, desc=None)[source]¶ Aggregate a sequence of sentence-level scores into a corpus-level score.
Parameters: - scores (
Sequence[LevenshteinScore]) – list of sentence-level scores. - desc (
Optional[Any]) – human-readable description.
Return type: Returns: Score object that is the aggregate of all sentence-level scores.
- scores (
- correct (
-
class
xnmt.eval.metrics.WERScore(correct, substitutions, insertions, deletions, desc=None)[source]¶ Bases:
xnmt.eval.metrics.LevenshteinScore,xnmt.persistence.SerializableClass to keep a word error rate.
-
class
xnmt.eval.metrics.CERScore(correct, substitutions, insertions, deletions, desc=None)[source]¶ Bases:
xnmt.eval.metrics.LevenshteinScore,xnmt.persistence.SerializableClass to keep a character error rate.
-
class
xnmt.eval.metrics.RecallScore(recall, hyp_len, ref_len, nbest=5, desc=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvalScore,xnmt.persistence.SerializableClass to keep a recall score.
Parameters: - recall (
Real) – recall score value between 0 and 1 - hyp_len (
Integral) – length of hypothesis - ref_len (
Integral) – length of reference - nbest (
Integral) – recall computed within n-best of specified n - desc (
Optional[Any]) – human-readable description to include in log outputs
-
higher_is_better()[source]¶ Return
Trueif higher values are favorable,Falseotherwise.Returns: Whether higher values are favorable.
-
score_str()[source]¶ A string representation of the evaluated score, potentially including additional statistics.
Returns: String representation of score.
-
static
aggregate(scores, desc=None)[source]¶ Aggregate a sequence of sentence-level scores into a corpus-level score.
Parameters: - scores (
Sequence[RecallScore]) – list of sentence-level scores. - desc (
Optional[Any]) – human-readable description.
Return type: Returns: Score object that is the aggregate of all sentence-level scores.
- scores (
- recall (
-
class
xnmt.eval.metrics.ExternalScore(value, higher_is_better=True, desc=None)[source]¶ Bases:
xnmt.eval.metrics.EvalScore,xnmt.persistence.SerializableClass to keep a score computed with an external tool.
Parameters: - value (
Real) – score value - higher_is_better (
bool) – whether higher scores or lower scores are favorable - desc (
Optional[Any]) – human-readable description to include in log outputs
- value (
-
class
xnmt.eval.metrics.SequenceAccuracyScore(num_correct, num_total, desc=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvalScore,xnmt.persistence.SerializableClass to keep a sequence accuracy score.
Parameters: - num_correct (
Integral) – number of correct outputs - num_total (
Integral) – number of total outputs - desc (
Optional[Any]) – human-readable description to include in log outputs
-
higher_is_better()[source]¶ Return
Trueif higher values are favorable,Falseotherwise.Returns: Whether higher values are favorable.
-
score_str()[source]¶ A string representation of the evaluated score, potentially including additional statistics.
Returns: String representation of score.
-
static
aggregate(scores, desc=None)[source]¶ Aggregate a sequence of sentence-level scores into a corpus-level score.
Parameters: - scores (
Sequence[SentenceLevelEvalScore]) – list of sentence-level scores. - desc (
Optional[Any]) – human-readable description.
Returns: Score object that is the aggregate of all sentence-level scores.
- scores (
- num_correct (
-
class
xnmt.eval.metrics.FMeasure(true_pos, false_neg, false_pos, desc=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvalScore,xnmt.persistence.Serializable-
higher_is_better()[source]¶ Return
Trueif higher values are favorable,Falseotherwise.Returns: Whether higher values are favorable.
-
score_str()[source]¶ A string representation of the evaluated score, potentially including additional statistics.
Returns: String representation of score.
-
static
aggregate(scores, desc=None)[source]¶ Aggregate a sequence of sentence-level scores into a corpus-level score.
Parameters: - scores (
Sequence[SentenceLevelEvalScore]) – list of sentence-level scores. - desc (
Optional[Any]) – human-readable description.
Returns: Score object that is the aggregate of all sentence-level scores.
- scores (
-
-
class
xnmt.eval.metrics.Evaluator[source]¶ Bases:
objectA template class to evaluate the quality of output.
-
evaluate(ref, hyp, desc=None)[source]¶ Calculate the quality of output given a reference.
Parameters: - ref (
Sequence[+T_co]) – list of reference sents ( a sentence is a list of tokens ) - hyp (
Sequence[+T_co]) – list of hypothesis sents ( a sentence is a list of tokens ) - desc (
Optional[Any]) – optional description that is passed on to score objects
Returns:
Return type: EvalScore- ref (
-
evaluate_multi_ref(ref, hyp, desc=None)[source]¶ Calculate the quality of output given multiple references.
Parameters: - ref (
Sequence[Sequence[+T_co]]) – list of tuples of reference sentences ( a sentence is a list of tokens ) - hyp (
Sequence[+T_co]) – list of hypothesis sentences ( a sentence is a list of tokens ) - desc (
Optional[Any]) – optional description that is passed on to score objects
Return type: - ref (
-
-
class
xnmt.eval.metrics.SentenceLevelEvaluator(write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.EvaluatorA template class for sentence-level evaluators.
Parameters: write_sentence_scores ( Optional[str]) – path of file to write sentence-level scores to (in YAML format)-
evaluate(ref, hyp, desc=None)[source]¶ Calculate the quality of output given a reference.
Parameters: - ref (
Sequence[+T_co]) – list of reference sents ( a sentence is a list of tokens ) - hyp (
Sequence[+T_co]) – list of hypothesis sents ( a sentence is a list of tokens ) - desc (
Optional[Any]) – optional description that is passed on to score objects
Returns:
Return type: SentenceLevelEvalScore- ref (
-
evaluate_multi_ref(ref, hyp, desc=None)[source]¶ Calculate the quality of output given multiple references.
Parameters: - ref (
Sequence[Sequence[+T_co]]) – list of tuples of reference sentences ( a sentence is a list of tokens ) - hyp (
Sequence[+T_co]) – list of hypothesis sentences ( a sentence is a list of tokens ) - desc (
Optional[Any]) – optional description that is passed on to score objects
Return type: - ref (
-
-
class
xnmt.eval.metrics.FastBLEUEvaluator(ngram=4, smooth=1)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableClass for computing BLEU scores using a fast Cython implementation.
Does not support multiple references. BLEU scores are computed according to K Papineni et al “BLEU: a method for automatic evaluation of machine translation”
Parameters: - ngram (
Integral) – consider ngrams up to this order (usually 4) - smooth (
Real) –
- ngram (
-
class
xnmt.eval.metrics.BLEUEvaluator(ngram=4)[source]¶ Bases:
xnmt.eval.metrics.Evaluator,xnmt.persistence.SerializableCompute BLEU scores against one or several references.
BLEU scores are computed according to K Papineni et al “BLEU: a method for automatic evaluation of machine translation”
Parameters: ngram ( Integral) – consider ngrams up to this order (usually 4)-
evaluate(ref, hyp, desc=None)[source]¶ Parameters: - ref (
Sequence[Sequence[str]]) – reference sentences (single-reference case: sentence is list of strings; - hyp (
Sequence[Sequence[str]]) – list of hypothesis sentences ( a sentence is a list of tokens ) - desc (
Optional[Any]) – description to pass on to returned score
Return type: Returns: Score, including intermediate results such as ngram ratio, sentence length, brevity penalty
- ref (
-
evaluate_multi_ref(ref, hyp, desc=None)[source]¶ Parameters: - ref (
Sequence[Sequence[Sequence[str]]]) – list of tuples of reference sentences ( a sentence is a list of tokens ) - hyp (
Sequence[Sequence[str]]) – list of hypothesis sentences ( a sentence is a list of tokens ) - desc (
Optional[Any]) – optional description that is passed on to score objects
Return type: Returns: Score, including intermediate results such as ngram ratio, sentence length, brevity penalty
- ref (
-
-
class
xnmt.eval.metrics.GLEUEvaluator(min_length=1, max_length=4, write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableClass for computing GLEU (Google BLEU) Scores.
GLEU scores are described in https://arxiv.org/pdf/1609.08144v2.pdf as follows:
“The BLEU score has some undesirable properties when used for single sentences, as it was designed to be a corpus measure. We therefore use a slightly different score for our RL experiments which we call the ‘GLEU score’. For the GLEU score, we record all sub-sequences of 1, 2, 3 or 4 tokens in output and target sequence (n-grams). We then compute a recall, which is the ratio of the number of matching n-grams to the number of total n-grams in the target (ground truth) sequence, and a precision, which is the ratio of the number of matching n-grams to the number of total n-grams in the generated output sequence. Then GLEU score is simply the minimum of recall and precision. This GLEU score’s range is always between 0 (no matches) and 1 (all match) and it is symmetrical when switching output and target. According to our experiments, GLEU score correlates quite well with the BLEU metric on a corpus level but does not have its drawbacks for our per sentence reward objective.”Parameters: - min_length (
Integral) – minimum n-gram order to consider - max_length (
Integral) – maximum n-gram order to consider - write_sentence_scores (
Optional[str]) – path of file to write sentence-level scores to (in YAML format)
- min_length (
-
class
xnmt.eval.metrics.WEREvaluator(case_sensitive=False, write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableA class to evaluate the quality of output in terms of word error rate.
Parameters: - case_sensitive (
bool) – whether scoring should be case-sensitive - write_sentence_scores (
Optional[str]) – path of file to write sentence-level scores to (in YAML format)
- case_sensitive (
-
class
xnmt.eval.metrics.CEREvaluator(case_sensitive=False, write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableA class to evaluate the quality of output in terms of character error rate.
Parameters: - case_sensitive (
bool) – whether scoring should be case-sensitive - write_sentence_scores (
Optional[str]) – path of file to write sentence-level scores to (in YAML format)
- case_sensitive (
-
class
xnmt.eval.metrics.ExternalEvaluator(path=None, higher_better=True)[source]¶ Bases:
xnmt.eval.metrics.Evaluator,xnmt.persistence.SerializableA class to evaluate the quality of the output according to an external evaluation script.
Does not support multiple references. The external script should only print a number representing the calculated score.
Parameters: - path (
Optional[str]) – path to external command line tool. - higher_better (
bool) – whether to interpret higher scores as favorable.
- path (
-
class
xnmt.eval.metrics.RecallEvaluator(nbest=5, write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableCompute recall by counting true positives.
Parameters: - nbest (
Integral) – compute recall within n-best of specified n - write_sentence_scores (
Optional[str]) – path of file to write sentence-level scores to (in YAML format)
-
evaluate(ref, hyp, desc=None)[source]¶ Calculate the quality of output given a reference.
Parameters: - ref – list of reference sents ( a sentence is a list of tokens )
- hyp – list of hypothesis sents ( a sentence is a list of tokens )
- desc – optional description that is passed on to score objects
Returns:
- nbest (
-
class
xnmt.eval.metrics.SequenceAccuracyEvaluator(case_sensitive=False, write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableA class to evaluate the quality of output in terms of sequence accuracy.
Parameters: - case_sensitive – whether differences in capitalization are to be considered
- write_sentence_scores (
Optional[str]) – path of file to write sentence-level scores to (in YAML format)
-
class
xnmt.eval.metrics.FMeasureEvaluator(pos_token='1', write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.SerializableA class to evaluate the quality of output in terms of classification F-score.
Parameters: - pos_token (
str) – token for the ‘positive’ class - write_sentence_scores (
Optional[str]) – path of file to write sentence-level scores to (in YAML format)
- pos_token (
-
class
xnmt.eval.metrics.SegmentationFMeasureEvaluator(write_sentence_scores=None)[source]¶ Bases:
xnmt.eval.metrics.SentenceLevelEvaluator,xnmt.persistence.Serializable
Data¶
Sentence¶
-
class
xnmt.sent.Sentence(idx=None, score=None)[source]¶ Bases:
objectA template class to represent a single data example of any type, used for both model input and output.
Parameters: - idx (
Optional[int]) – running sentence number (0-based; unique among sentences loaded from the same file, but not across files) - score (
Optional[Real]) – a score given to this sentence by a model
-
len_unpadded()[source]¶ Return length of input prior to applying any padding.
Returns: unpadded length
Return type: int
-
create_padded_sent(pad_len)[source]¶ Return a new, padded version of the sentence (or self if pad_len is zero).
Parameters: pad_len ( Integral) – number of tokens to appendReturn type: SentenceReturns: padded sentence
- idx (
-
class
xnmt.sent.ReadableSentence(idx, score=None, output_procs=[])[source]¶ Bases:
xnmt.sent.SentenceA base class for sentences based on readable strings.
Parameters: - idx (
Integral) – running sentence number (0-based; unique among sentences loaded from the same file, but not across files) - score (
Optional[Real]) – a score given to this sentence by a model - output_procs (
Union[OutputProcessor,Sequence[OutputProcessor]]) – output processors to be applied when calling sent_str()
-
str_tokens(**kwargs)[source]¶ Return list of readable string tokens.
Parameters: **kwargs – should accept arbitrary keyword args Returns: list of tokens.
Return type: List[str]
-
sent_str(custom_output_procs=None, **kwargs)[source]¶ Return a single string containing the readable version of the sentence.
Parameters: - custom_output_procs – if not None, overwrite the sentence’s default output processors
- **kwargs – should accept arbitrary keyword args
Returns: readable string
Return type: str
- idx (
-
class
xnmt.sent.ScalarSentence(value, idx=None, vocab=None, score=None)[source]¶ Bases:
xnmt.sent.ReadableSentenceA sentence represented by a single integer value, optionally interpreted via a vocab.
This is useful for classification-style problems.
Parameters: - value (
Integral) – scalar value - idx (
Optional[Integral]) – running sentence number (0-based; unique among sentences loaded from the same file, but not across files) - vocab (
Optional[Vocab]) – optional vocab to give different scalar values a string representation. - score (
Optional[Real]) – a score given to this sentence by a model
-
len_unpadded()[source]¶ Return length of input prior to applying any padding.
Returns: unpadded length
Return type: int
-
create_padded_sent(pad_len)[source]¶ Return a new, padded version of the sentence (or self if pad_len is zero).
Parameters: pad_len ( Integral) – number of tokens to appendReturn type: ScalarSentenceReturns: padded sentence
-
create_truncated_sent(trunc_len)[source]¶ Create a new, right-truncated version of the sentence (or self if trunc_len is zero).
Parameters: trunc_len ( Integral) – number of tokens to truncateReturn type: ScalarSentenceReturns: truncated sentence
- value (
-
class
xnmt.sent.CompoundSentence(sents)[source]¶ Bases:
xnmt.sent.SentenceA compound sentence contains several sentence objects that present different ‘views’ on the same data examples.
Parameters: sents ( Sequence[Sentence]) – a list of sentences-
len_unpadded()[source]¶ Return length of input prior to applying any padding.
Returns: unpadded length
Return type: int
-
create_padded_sent(pad_len)[source]¶ Return a new, padded version of the sentence (or self if pad_len is zero).
Parameters: pad_len – number of tokens to append Returns: padded sentence
-
-
class
xnmt.sent.SimpleSentence(words, idx=None, vocab=None, score=None, output_procs=[], pad_token=1, unpadded_sent=None)[source]¶ Bases:
xnmt.sent.ReadableSentenceA simple sentence, represented as a list of tokens
Parameters: - words (
Sequence[Integral]) – list of integer word ids - idx (
Optional[Integral]) – running sentence number (0-based; unique among sentences loaded from the same file, but not across files) - vocab (
Optional[Vocab]) – optionally vocab mapping word ids to strings - score (
Optional[Real]) – a score given to this sentence by a model - output_procs (
Union[OutputProcessor,Sequence[OutputProcessor]]) – output processors to be applied when calling sent_str() - pad_token (
Integral) – special token used for padding - unpadded_sent (
Optional[SimpleSentence]) – reference to original, unpadded sentence if available
-
create_padded_sent(pad_len)[source]¶ Return a new, padded version of the sentence (or self if pad_len is zero).
Parameters: pad_len ( Integral) – number of tokens to appendReturn type: SimpleSentenceReturns: padded sentence
-
create_truncated_sent(trunc_len)[source]¶ Create a new, right-truncated version of the sentence (or self if trunc_len is zero).
Parameters: trunc_len ( Integral) – number of tokens to truncateReturn type: SimpleSentenceReturns: truncated sentence
- words (
-
class
xnmt.sent.SegmentedSentence(segment=[], **kwargs)[source]¶ Bases:
xnmt.sent.SimpleSentence
-
class
xnmt.sent.ArraySentence(nparr, idx=None, padded_len=0, score=None, unpadded_sent=None)[source]¶ Bases:
xnmt.sent.SentenceA sentence based on a numpy array containing a continuous-space vector for each token.
Parameters: - idx (
Optional[Integral]) – running sentence number (0-based; unique among sentences loaded from the same file, but not across files) - nparr (
ndarray) – numpy array of dimension num_tokens x token_size - padded_len (
Integral) – how many padded tokens are contained in the given nparr - score (
Optional[Real]) – a score given to this sentence by a model
-
len_unpadded()[source]¶ Return length of input prior to applying any padding.
Returns: unpadded length
-
create_padded_sent(pad_len)[source]¶ Return a new, padded version of the sentence (or self if pad_len is zero).
Parameters: pad_len ( Integral) – number of tokens to appendReturn type: ArraySentenceReturns: padded sentence
-
create_truncated_sent(trunc_len)[source]¶ Create a new, right-truncated version of the sentence (or self if trunc_len is zero).
Parameters: trunc_len ( Integral) – number of tokens to truncateReturn type: ArraySentenceReturns: truncated sentence
- idx (
-
class
xnmt.sent.NbestSentence(base_sent, nbest_id, print_score=False)[source]¶ Bases:
xnmt.sent.SimpleSentenceOutput in the context of an nbest list.
Parameters: - base_sent (
SimpleSentence) – The base sent object - nbest_id (
Integral) – The sentence id in the nbest list - print_score (
bool) – If True, print nbest_id, score, content separated by|||. If False, drop the score.
-
sent_str(custom_output_procs=None, **kwargs)[source]¶ Return a single string containing the readable version of the sentence.
Parameters: - custom_output_procs – if not None, overwrite the sentence’s default output processors
- **kwargs – should accept arbitrary keyword args
Returns: readable string
Return type: str
- base_sent (
-
class
xnmt.sent.GraphSentence(idx, graph, vocab, num_padded=0, unpadded_sent=None)[source]¶ Bases:
xnmt.sent.ReadableSentenceA graph structure.
This is a wrapper for a graph datastructure.
Parameters: - idx (
Optional[Integral]) – running sentence number (0-based; unique among sentences loaded from the same file, but not across files) - graph (
HyperGraph) – hypergraph containing graphs - vocab (
Vocab) – vocabulary for word IDs - num_padded (
Integral) – denoting that this many words are padded (without adding any physical nodes) - unpadded_sent (
Optional[GraphSentence]) – reference to original, unpadded sentence if available
-
sent_len()[source]¶ Return number of nodes in the graph, including padded words.
Return type: intReturns: Number of nodes in graph.
-
len_unpadded()[source]¶ Return number of nodes in the graph, without counting padded words.
Return type: intReturns: Number of nodes in graph.
-
create_padded_sent(pad_len)[source]¶ Return padded graph.
Parameters: pad_len ( Integral) – Number of tokens to pad.Return type: GraphSentenceReturns: New padded graph, or self if pad_len==0.
-
create_truncated_sent(trunc_len)[source]¶ Return self, as truncation is not supported.
Parameters: trunc_len ( Integral) – Number of tokens to truncate, must be 0.Return type: GraphSentenceReturns: self.
-
get_unpadded_sent()[source]¶ Return the unpadded sentence.
If self is unpadded, return self, if not return reference to original unpadded sentence if possible, otherwise create a new sentence.
Return type: GraphSentence
-
reversed()[source]¶ Create a graph with reversed direction.
The new graph will have graph nodes in reversed order and switched successors/predecessors. It will have the same number of padded nodes (again at the end of the nodes!).
Return type: GraphSentenceReturns: Reversed graph.
- idx (
-
class
xnmt.sent.LatticeNode(node_id, value, fwd_log_prob=0, marginal_log_prob=0, bwd_log_prob=0)[source]¶ Bases:
xnmt.graph.HyperNodeA lattice node.
Parameters: - node_id (
int) – Unique identifier for node - value (
Integral) – Word id assigned to this node. - fwd_log_prob (
Optional[Real]) – Lattice log probability normalized in forward-direction (successors sum to 1) - marginal_log_prob (
Optional[Real]) – Lattice log probability globally normalized - bwd_log_prob (
Optional[Real]) – Lattice log probability normalized in backward-direction (predecessors sum to 1)
- node_id (
-
class
xnmt.sent.SyntaxTreeNode(node_id, value, head, node_type=<Type.NONE: 0>)[source]¶ Bases:
xnmt.graph.HyperNode
-
class
xnmt.sent.RNNGSequenceSentence(idx, graph, surface_vocab, nt_vocab, all_surfaces=False, num_padded=0, unpadded_sent=None)[source]¶ Bases:
xnmt.sent.ReadableSentence-
len_unpadded()[source]¶ Return length of input prior to applying any padding.
Returns: unpadded length
Return type: int
-
create_padded_sent(pad_len)[source]¶ Return a new, padded version of the sentence (or self if pad_len is zero).
Parameters: pad_len ( Integral) – number of tokens to appendReturn type: ScalarSentenceReturns: padded sentence
-
create_truncated_sent(trunc_len)[source]¶ Create a new, right-truncated version of the sentence (or self if trunc_len is zero).
Parameters: trunc_len ( Integral) – number of tokens to truncateReturn type: ScalarSentenceReturns: truncated sentence
-
get_unpadded_sent()[source]¶ Return the unpadded sentence.
If self is unpadded, return self, if not return reference to original unpadded sentence if possible, otherwise create a new sentence.
-
InputReader¶
-
class
xnmt.input_readers.InputReader[source]¶ Bases:
objectA base class to read in a file and turn it into an input
-
read_sents(filename, filter_ids=None)[source]¶ Read sentences and return an iterator.
Parameters: - filename (
str) – data file - filter_ids (
Optional[Sequence[Integral]]) – only read sentences with these ids (0-indexed)
Returns: iterator over sentences from filename
Return type: Iterator[Sentence]- filename (
-
-
class
xnmt.input_readers.BaseTextReader[source]¶
-
class
xnmt.input_readers.PlainTextReader(vocab=None, read_sent_len=False, output_proc=[])[source]¶ Bases:
xnmt.input_readers.BaseTextReader,xnmt.persistence.SerializableHandles the typical case of reading plain text files, with one sent per line.
Parameters: - vocab (
Optional[Vocab]) – Vocabulary to convert string tokens to integer ids. If not given, plain text will be assumed to contain space-separated integer ids. - read_sent_len (
bool) – if set, read the length of each sentence instead of the sentence itself. EOS is not counted. - output_proc (
Sequence[OutputProcessor]) – output processors to revert the created sentences back to a readable string
- vocab (
-
class
xnmt.input_readers.CompoundReader(readers, vocab=None)[source]¶ Bases:
xnmt.input_readers.InputReader,xnmt.persistence.SerializableA compound reader reads inputs using several input readers at the same time.
The resulting inputs will be of type
sent.CompoundSentence, which holds the results from the different readers as a tuple. Inputs can be read from different locations (if input file name is a sequence of filenames) or all from the same location (if it is a string). The latter can be used to read the same inputs using several input different readers which might capture different aspects of the input data.Parameters: - readers (
Sequence[InputReader]) – list of input readers to use - vocab (
Optional[Vocab]) – not used by this reader, but some parent components may require access to the vocab.
-
read_sents(filename, filter_ids=None)[source]¶ Read sentences and return an iterator.
Parameters: - filename (
Union[str,Sequence[str]]) – data file - filter_ids (
Optional[Sequence[Integral]]) – only read sentences with these ids (0-indexed)
Returns: iterator over sentences from filename
Return type: Iterator[Sentence]- filename (
- readers (
-
class
xnmt.input_readers.SentencePieceTextReader(model_file, sample_train=False, l=-1, alpha=0.1, vocab=None, output_proc=[<class 'xnmt.output.JoinPieceTextOutputProcessor'>])[source]¶ Bases:
xnmt.input_readers.BaseTextReader,xnmt.persistence.SerializableRead in text and segment it with sentencepiece. Optionally perform sampling for subword regularization, only at training time. https://arxiv.org/pdf/1804.10959.pdf
-
read_sent(line, idx)[source]¶ Convert a raw text line into an input object.
Parameters: - line (
str) – a single input string - idx (
Integral) – sentence number
Returns: a SentenceInput object for the input sentence
Return type: SimpleSentence- line (
-
-
class
xnmt.input_readers.RamlTextReader(tau=1.0, vocab=None, output_proc=[])[source]¶ Bases:
xnmt.input_readers.BaseTextReader,xnmt.persistence.SerializableHandles the RAML sampling, can be used on the target side, or on both the source and target side. Randomly replaces words according to Hamming Distance. https://arxiv.org/pdf/1808.07512.pdf https://arxiv.org/pdf/1609.00150.pdf
-
read_sent(line, idx)[source]¶ Convert a raw text line into an input object.
Parameters: - line (
str) – a single input string - idx (
Integral) – sentence number
Returns: a SentenceInput object for the input sentence
Return type: SimpleSentence- line (
-
-
class
xnmt.input_readers.CharFromWordTextReader(vocab=None, read_sent_len=False, output_proc=[])[source]¶ Bases:
xnmt.input_readers.PlainTextReader,xnmt.persistence.SerializableRead in word based corpus and turned that into SegmentedSentence. SegmentedSentece’s words are characters, but it contains the information of the segmentation.
x = SegmentedSentence(“i code today”) (TRUE) x.words == [“i”, “c”, “o”, “d”, “e”, “t”, “o”, “d”, “a”, “y”] (TRUE) x.segment == [0, 4, 9]
It means that the segmentation (end of words) happen in the 0th, 4th and 9th position of the char sequence.
-
read_sent(line, idx)[source]¶ Convert a raw text line into an input object.
Parameters: - line (
str) – a single input string - idx (
Integral) – sentence number
Returns: a SentenceInput object for the input sentence
Return type: SegmentedSentence- line (
-
-
class
xnmt.input_readers.H5Reader(transpose=False, feat_from=None, feat_to=None, feat_skip=None, timestep_skip=None, timestep_truncate=None)[source]¶ Bases:
xnmt.input_readers.InputReader,xnmt.persistence.SerializableHandles the case where sents are sequences of continuous-space vectors.
The input is a “.h5” file, which can be created for example using xnmt.preproc.MelFiltExtractor
The data items are assumed to be labeled with integers 0, 1, .. (converted to strings).
Each data item will be a 2D matrix representing a sequence of vectors. They can be in either order, depending on the value of the “transpose” variable: * sents[sent_id][feat_ind,timestep] if transpose=False * sents[sent_id][timestep,feat_ind] if transpose=True
Parameters: - transpose (
bool) – whether inputs are transposed or not. - feat_from (
Optional[Integral]) – use feature dimensions in a range, starting at this index (inclusive) - feat_to (
Optional[Integral]) – use feature dimensions in a range, ending at this index (exclusive) - feat_skip (
Optional[Integral]) – stride over features - timestep_skip (
Optional[Integral]) – stride over timesteps - timestep_truncate (
Optional[Integral]) – cut off timesteps if sequence is longer than specified value
-
read_sents(filename, filter_ids=None)[source]¶ Read sentences and return an iterator.
Parameters: - filename (
str) – data file - filter_ids (
Optional[Sequence[Integral]]) – only read sentences with these ids (0-indexed)
Returns: iterator over sentences from filename
Return type: Iterator[ArraySentence]- filename (
- transpose (
-
class
xnmt.input_readers.NpzReader(transpose=False, feat_from=None, feat_to=None, feat_skip=None, timestep_skip=None, timestep_truncate=None)[source]¶ Bases:
xnmt.input_readers.InputReader,xnmt.persistence.SerializableHandles the case where sents are sequences of continuous-space vectors.
The input is a “.npz” file, which consists of multiply “.npy” files, each corresponding to a single sequence of continuous features. This can be created in two ways: * Use the builtin function numpy.savez_compressed() * Create a bunch of .npy files, and run “zip” on them to zip them into an archive.
The file names should be named XXX_0, XXX_1, etc., where the final number after the underbar indicates the order of the sequence in the corpus. This is done automatically by numpy.savez_compressed(), in which case the names will be arr_0, arr_1, etc.
Each numpy file will be a 2D matrix representing a sequence of vectors. They can be in either order, depending on the value of the “transpose” variable. * sents[sent_id][feat_ind,timestep] if transpose=False * sents[sent_id][timestep,feat_ind] if transpose=True
Parameters: - transpose (
bool) – whether inputs are transposed or not. - feat_from (
Optional[Integral]) – use feature dimensions in a range, starting at this index (inclusive) - feat_to (
Optional[Integral]) – use feature dimensions in a range, ending at this index (exclusive) - feat_skip (
Optional[Integral]) – stride over features - timestep_skip (
Optional[Integral]) – stride over timesteps - timestep_truncate (
Optional[Integral]) – cut off timesteps if sequence is longer than specified value
- transpose (
-
class
xnmt.input_readers.IDReader[source]¶ Bases:
xnmt.input_readers.BaseTextReader,xnmt.persistence.SerializableHandles the case where we need to read in a single ID (like retrieval problems).
Files must be text files containing a single integer per line.
-
read_sent(line, idx)[source]¶ Convert a raw text line into an input object.
Parameters: - line (
str) – a single input string - idx (
Integral) – sentence number
Returns: a SentenceInput object for the input sentence
Return type: ScalarSentence- line (
-
-
class
xnmt.input_readers.CoNLLToRNNGActionsReader(surface_vocab, nt_vocab)[source]¶ Bases:
xnmt.input_readers.BaseTextReader,xnmt.persistence.SerializableHandles the reading of CoNLL File Format:
ID FORM LEMMA POS FEAT HEAD DEPREL
A single line represents a single edge of dependency parse tree.
-
class
xnmt.input_readers.LatticeReader(vocab, text_input=False, flatten=False)[source]¶ Bases:
xnmt.input_readers.BaseTextReader,xnmt.persistence.SerializableReads lattices from a text file.
The expected lattice file format is as follows: * 1 line per lattice * lines are serialized python lists / tuples * 2 lists per lattice: - list of nodes, with every node a 4-tuple: (lexicon_entry, fwd_log_prob, marginal_log_prob, bwd_log_prob) - list of arcs, each arc a tuple: (node_id_start, node_id_end) - node_id references the nodes and is 0-indexed - node_id_start < node_id_end * All paths must share a common start and end node, i.e. <s> and </s> need to be contained in the lattice
- A simple example lattice:
- [(‘<s>’, 0.0, 0.0, 0.0), (‘buenas’, 0, 0.0, 0.0), (‘tardes’, 0, 0.0, 0.0), (‘</s>’, 0.0, 0.0, 0.0)],[(0, 1), (1, 2), (2, 3)]
Parameters: - vocab (
Vocab) – Vocabulary to convert string tokens to integer ids. If not given, plain text will be assumed to contain space-separated integer ids. - text_input (
bool) – IfTrue, assume a standard text file as input and convert it to a flat lattice. - flatten – If
True, convert to a flat lattice, with all probabilities set to 1.
-
xnmt.input_readers.read_parallel_corpus(src_reader, trg_reader, src_file, trg_file, batcher=None, sample_sents=None, max_num_sents=None, max_src_len=None, max_trg_len=None)[source]¶ A utility function to read a parallel corpus.
Parameters: - src_reader (
InputReader) – - trg_reader (
InputReader) – - src_file (
str) – - trg_file (
str) – - batcher (
Optional[Batcher]) – - sample_sents (
Optional[Integral]) – if not None, denote the number of sents that should be randomly chosen from all available sents. - max_num_sents (
Optional[Integral]) – if not None, read only the first this many sents - max_src_len (
Optional[Integral]) – skip pair if src side is too long - max_trg_len (
Optional[Integral]) – skip pair if trg side is too long
Return type: tupleReturns: A tuple of (src_data, trg_data, src_batches, trg_batches) where
*_batches = *_dataifbatcher=None- src_reader (
Vocab¶
-
class
xnmt.vocabs.Vocab(i2w=None, vocab_file=None, sentencepiece_vocab=False)[source]¶ Bases:
xnmt.persistence.SerializableAn open vocabulary that converts between strings and integer ids.
The open vocabulary is realized via a special unknown-word token that is used whenever a word is not inside the list of known tokens. This class is immutable, i.e. its contents are not to change after the vocab has been initialized.
For initialization, i2w or vocab_file must be specified, but not both.
Parameters: - i2w (
Optional[Sequence[str]]) – complete list of known words, including<s>and</s>. - vocab_file (
Optional[str]) – file containing one word per line, and not containing <s>, </s>, <unk> - sentencepiece_vocab (
bool) – Set toTrueifvocab_fileis the output of the sentencepiece tokenizer. Defaults toFalse.
-
static
i2w_from_vocab_file(vocab_file, sentencepiece_vocab=False)[source]¶ Load the vocabulary from a file.
If
sentencepiece_vocabis set to True, this will accept a sentencepiece vocabulary fileParameters: - vocab_file (
str) – file containing one word per line, and not containing<s>,</s>,<unk> - sentencepiece_vocab (bool) – Set to
Trueifvocab_fileis the output of the sentencepiece tokenizer. Defaults toFalse.
Return type: List[str]- vocab_file (
- i2w (
Batcher¶
-
class
xnmt.batchers.ListBatch(batch_elements, mask=None)[source]¶ Bases:
list,xnmt.batchers.BatchA class containing a minibatch of things.
This class behaves like a Python list, but adds semantics that the contents form a (mini)batch of things. An optional mask can be specified to indicate padded parts of the inputs. Should be treated as an immutable object.
Parameters: - batch_elements (
list) – list of things - mask (
Optional[Mask]) – optional mask when batch contains items of unequal size
- batch_elements (
-
class
xnmt.batchers.CompoundBatch(*batch_elements)[source]¶ Bases:
xnmt.batchers.BatchA compound batch contains several parallel batches.
Parameters: *batch_elements – one or several batches
-
class
xnmt.batchers.Mask(np_arr)[source]¶ Bases:
objectAn immutable mask specifies padded parts in a sequence or batch of sequences.
Masks are represented as numpy array of dimensions batchsize x seq_len, with parts belonging to the sequence set to 0, and parts that should be masked set to 1
Parameters: np_arr ( ndarray) – numpy array-
cmult_by_timestep_expr(expr, timestep, inverse=False)[source]¶ Parameters: - expr (
Expression) – a dynet expression corresponding to one timestep - timestep (
Integral) – index of current timestep - inverse (
bool) – True will keep the unmasked parts, False will zero out the unmasked parts
Return type: Expression- expr (
-
-
class
xnmt.batchers.Batcher(batch_size, granularity='sent', pad_src_to_multiple=1, sort_within_by_trg_len=True)[source]¶ Bases:
objectA template class to convert a list of sentences to several batches of sentences.
Parameters: - batch_size (
Integral) – batch size - granularity (
str) – ‘sent’ or ‘word’ - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer. - sort_within_by_trg_len (
bool) – whether to sort by reverse trg len inside a batch
-
is_random()[source]¶ Return type: boolReturns: True if there is some randomness in the batching process, False otherwise.
-
create_single_batch(src_sents, trg_sents=None, sort_by_trg_len=False)[source]¶ Create a single batch, either source-only or source-and-target.
Parameters: Return type: Returns: a tuple of batches if targets were given, otherwise a single batch
- batch_size (
-
class
xnmt.batchers.InOrderBatcher(batch_size=1, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.Batcher,xnmt.persistence.SerializableA class to create batches in order of the original corpus, both across and within batches.
Parameters: - batch_size (
Integral) – batch size - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.ShuffleBatcher(batch_size, granularity='sent', pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.BatcherA template class to create batches through randomly shuffling without sorting.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - granularity (
str) – ‘sent’ or ‘word’ - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.SortBatcher(batch_size, granularity='sent', sort_key=<function SortBatcher.<lambda>>, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.BatcherA template class to create batches through bucketing sentence length.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - granularity (
str) – ‘sent’ or ‘word’ - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
xnmt.batchers.mark_as_batch(data, mask=None)[source]¶ Mark a sequence of items as batch
Parameters: - data (
Sequence[+T_co]) – sequence of things - mask (
Optional[Mask]) – optional mask
Returns: a batch of things
Return type: Batch- data (
-
xnmt.batchers.is_batched(data)[source]¶ Check whether some data is batched.
Parameters: data ( Sequence[+T_co]) – data to checkReturn type: boolReturns: True iff data is batched.
-
xnmt.batchers.pad(batch, pad_to_multiple=1)[source]¶ Apply padding to sentences in a batch.
Parameters: - batch (
Sequence[+T_co]) – batch of sentences - pad_to_multiple (
Integral) – pad sentences so their length is a multiple of this integer.
Return type: Returns: batch containing padded items and a corresponding batch mask.
- batch (
-
class
xnmt.batchers.SrcBatcher(batch_size, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.SortBatcher,xnmt.persistence.SerializableA batcher that creates fixed-size batches, grouped by src len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.TrgBatcher(batch_size, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.SortBatcher,xnmt.persistence.SerializableA batcher that creates fixed-size batches, grouped by trg len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.SrcTrgBatcher(batch_size, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.SortBatcher,xnmt.persistence.SerializableA batcher that creates fixed-size batches, grouped by src len, then trg len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.TrgSrcBatcher(batch_size, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.SortBatcher,xnmt.persistence.SerializableA batcher that creates fixed-size batches, grouped by trg len, then src len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.SentShuffleBatcher(batch_size, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.ShuffleBatcher,xnmt.persistence.SerializableA batcher that creates fixed-size batches of random order.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - batch_size (
Integral) – batch size - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- batch_size (
-
class
xnmt.batchers.WordShuffleBatcher(words_per_batch, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.ShuffleBatcher,xnmt.persistence.SerializableA batcher that creates fixed-size batches, grouped by src len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - words_per_batch (
Integral) – number of src+trg words in each batch - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- words_per_batch (
-
class
xnmt.batchers.WordSortBatcher(words_per_batch, avg_batch_size, sort_key, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.SortBatcherBase class for word sort-based batchers.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - words_per_batch (
Optional[Integral]) – number of src+trg words in each batch - avg_batch_size (
Optional[Real]) – avg number of sentences in each batch (if words_per_batch not given) - sort_key (
Callable) – - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- words_per_batch (
-
class
xnmt.batchers.WordSrcBatcher(words_per_batch=None, avg_batch_size=None, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.WordSortBatcher,xnmt.persistence.SerializableA batcher that creates variable-sized batches with given average (src+trg) words per batch, grouped by src len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - words_per_batch (
Optional[Integral]) – number of src+trg words in each batch - avg_batch_size (
Optional[Real]) – avg number of sentences in each batch (if words_per_batch not given) - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- words_per_batch (
-
class
xnmt.batchers.WordTrgBatcher(words_per_batch=None, avg_batch_size=None, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.WordSortBatcher,xnmt.persistence.SerializableA batcher that creates variable-sized batches with given average (src+trg) words per batch, grouped by trg len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - words_per_batch (
Optional[Integral]) – number of src+trg words in each batch - avg_batch_size (
Optional[Real]) – avg number of sentences in each batch (if words_per_batch not given) - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- words_per_batch (
-
class
xnmt.batchers.WordSrcTrgBatcher(words_per_batch=None, avg_batch_size=None, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.WordSortBatcher,xnmt.persistence.SerializableA batcher that creates variable-sized batches with given average number of src + trg words per batch, grouped by src len, then trg len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - words_per_batch (
Optional[Integral]) – number of src+trg words in each batch - avg_batch_size (
Optional[Real]) – avg number of sentences in each batch (if words_per_batch not given) - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- words_per_batch (
-
class
xnmt.batchers.WordTrgSrcBatcher(words_per_batch=None, avg_batch_size=None, break_ties_randomly=True, pad_src_to_multiple=1)[source]¶ Bases:
xnmt.batchers.WordSortBatcher,xnmt.persistence.SerializableA batcher that creates variable-sized batches with given average number of src + trg words per batch, grouped by trg len, then src len.
Sentences inside each batch are sorted by reverse trg length.
Parameters: - words_per_batch (
Optional[Integral]) – number of src+trg words in each batch - avg_batch_size (
Optional[Real]) – avg number of sentences in each batch (if words_per_batch not given) - break_ties_randomly (
bool) – if True, randomly shuffle sentences of the same src length before creating batches. - pad_src_to_multiple (
Integral) – pad source sentences so its length is multiple of this integer.
- words_per_batch (
-
xnmt.batchers.truncate_batches(*xl)[source]¶ Truncate a list of batched items so that all items have the batch size of the input with the smallest batch size.
Inputs can be of various types and would usually correspond to a single time step. Assume that the batch elements with index 0 correspond across the inputs, so that batch elements will be truncated from the top, i.e. starting with the highest-indexed batch elements. Masks are not considered even if attached to a input of
Batchtype.Parameters: *xl – batched timesteps of various types Return type: Sequence[Union[Expression,Batch,Mask,UniLSTMState]]Returns: Copies of the inputs, truncated to consistent batch size.
Preprocessing¶
-
class
xnmt.preproc.PreprocRunner(tasks=None, overwrite=False)[source]¶ Bases:
xnmt.persistence.SerializablePreprocess and filter the input files, and create the vocabulary.
Parameters: - tasks (
Optional[List[PreprocTask]]) – A list of preprocessing steps, usually parametrized by in_files (the input files), out_files (the output files), and spec for that particular preprocessing type The types of arguments that preproc_spec expects: * Option(“in_files”, help_str=”list of paths to the input files”), * Option(“out_files”, help_str=”list of paths for the output files”), * Option(“spec”, help_str=”The specifications describing which type of processing to use. For normalize and vocab, should consist of the ‘lang’ and ‘spec’, where ‘lang’ can either be ‘all’ to apply the same type of processing to all languages, or a zero-indexed integer indicating which language to process.”), - overwrite (
bool) – Whether to overwrite files if they already exist.
- tasks (
-
class
xnmt.preproc.PreprocExtract(in_files, out_files, specs)[source]¶ Bases:
xnmt.preproc.PreprocTask,xnmt.persistence.Serializable
-
class
xnmt.preproc.PreprocTokenize(in_files, out_files, specs)[source]¶ Bases:
xnmt.preproc.PreprocTask,xnmt.persistence.Serializable
-
class
xnmt.preproc.PreprocNormalize(in_files, out_files, specs)[source]¶ Bases:
xnmt.preproc.PreprocTask,xnmt.persistence.Serializable
-
class
xnmt.preproc.PreprocFilter(in_files, out_files, specs)[source]¶ Bases:
xnmt.preproc.PreprocTask,xnmt.persistence.Serializable
-
class
xnmt.preproc.PreprocVocab(in_files, out_files, specs)[source]¶ Bases:
xnmt.preproc.PreprocTask,xnmt.persistence.Serializable
-
class
xnmt.preproc.Normalizer[source]¶ Bases:
objectA type of normalization to perform to a file. It is initialized first, then expanded.
-
class
xnmt.preproc.NormalizerLower[source]¶ Bases:
xnmt.preproc.Normalizer,xnmt.persistence.SerializableLowercase the text.
-
class
xnmt.preproc.NormalizerRemovePunct(remove_inside_word=False, allowed_chars='')[source]¶ Bases:
xnmt.preproc.Normalizer,xnmt.persistence.SerializableRemove punctuation from the text.
Parameters: - remove_inside_word (
bool) – IfFalse, only remove punctuation appearing adjacent to white space. - allowed_chars (
str) – Specify punctuation that is allowed and should not be removed.
- remove_inside_word (
-
class
xnmt.preproc.Tokenizer[source]¶ Bases:
xnmt.preproc.NormalizerPass the text through an internal or external tokenizer.
TODO: only StreamTokenizers are supported by the preproc runner right now.
-
class
xnmt.preproc.BPETokenizer(vocab_size, train_files)[source]¶ Bases:
xnmt.preproc.Tokenizer,xnmt.persistence.SerializableClass for byte-pair encoding tokenizer.
TODO: Unimplemented
-
class
xnmt.preproc.CharacterTokenizer[source]¶ Bases:
xnmt.preproc.Tokenizer,xnmt.persistence.SerializableTokenize into characters, with __ indicating blank spaces
-
class
xnmt.preproc.UnicodeTokenizer(use_merge_symbol=True, merge_symbol='↹', reverse=False)[source]¶ Bases:
xnmt.preproc.Tokenizer,xnmt.persistence.SerializableTokenizer that inserts whitespace between words and punctuation.
This tokenizer is language-agnostic and (optionally) reversible, and is based on unicode character categories. See appendix of https://arxiv.org/pdf/1804.08205
Parameters: - use_merge_symbol (
bool) – whether to prepend a merge-symbol so that the tokenization becomes reversible - merge_symbol (
str) – the merge symbol to use - reverse (
bool) – whether to reverse tokenization (assumes use_merge_symbol=True was used in forward direction)
- use_merge_symbol (
-
class
xnmt.preproc.ExternalTokenizer(path, tokenizer_args=None, arg_separator=' ')[source]¶ Bases:
xnmt.preproc.Tokenizer,xnmt.persistence.SerializableClass for arbitrary external tokenizer that accepts untokenized text to stdin and emits tokenized tezt to stdout, with passable parameters.
It is assumed that in general, external tokenizers will be more efficient when run once per file, so are run as such (instead of one-execution-per-line.)
Parameters: - path (
str) – - tokenizer_args (
Optional[Sequence[str]]) – - arg_separator (
str) –
- path (
-
class
xnmt.preproc.SentencepieceTokenizer(train_files, vocab_size, overwrite=False, model_prefix='sentpiece', output_format='piece', model_type='bpe', hard_vocab_limit=True, encode_extra_options=None, decode_extra_options=None)[source]¶ Bases:
xnmt.preproc.Tokenizer,xnmt.persistence.SerializableSentencepiece tokenizer The options supported by the SentencepieceTokenizer are almost exactly those presented in the Sentencepiece readme, namely:
Parameters: - train_files (
Sequence[str]) – - vocab_size (
Integral) – fixes the vocabulary size - overwrite (
bool) – - model_prefix (
str) – The trained bpe model will be saved under{model_prefix}.model/.vocab - output_format (
str) – - model_type (
str) – Eitherunigram(default),bpe,charorword. Please refer to the sentencepiece documentation for more details - hard_vocab_limit (
bool) – setting this toFalsewill make the vocab size a soft limit. Useful for small datasets. This isTrueby default. - encode_extra_options (
Optional[str]) – - decode_extra_options (
Optional[str]) –
- train_files (
-
class
xnmt.preproc.SentenceFilterer(spec)[source]¶ Bases:
objectFilters sentences that don’t match a criterion.
-
keep(sents)[source]¶ Takes a list of inputs/outputs for a single sentence and decides whether to keep them.
In general, these inputs/outpus should already be segmented into words, so len() will return the number of words, not the number of characters.
Parameters: sents ( list) – A list of parallel sentences.Return type: boolReturns: True if they should be used or False if they should be filtered.
-
-
class
xnmt.preproc.SentenceFiltererMatchingRegex(regex_src, regex_trg, regex_all)[source]¶ Bases:
xnmt.preproc.SentenceFiltererFilters sentences via regular expressions. A sentence must match the expression to be kept.
-
class
xnmt.preproc.SentenceFiltererLength(min_src=None, max_src=None, min_trg=None, max_trg=None, min_all=None, max_all=None)[source]¶ Bases:
xnmt.preproc.SentenceFilterer,xnmt.persistence.SerializableFilters sentences by length
-
class
xnmt.preproc.VocabFiltererFreq(min_freq)[source]¶ Bases:
xnmt.preproc.VocabFilterer,xnmt.persistence.SerializableFilter the vocabulary, removing words below a particular minimum frequency
-
class
xnmt.preproc.VocabFiltererRank(max_rank)[source]¶ Bases:
xnmt.preproc.VocabFilterer,xnmt.persistence.SerializableFilter the vocabulary, removing words above a particular frequency rank
-
class
xnmt.preproc.MelFiltExtractor(nfilt=40, delta=False)[source]¶ Bases:
xnmt.preproc.Extractor,xnmt.persistence.Serializable-
extract_to(in_file, out_file)[source]¶ Parameters: - in_file (
str) – yaml file that contains a list of dictionaries. Each dictionary contains: - wav (str): path to wav file - offset (float): start time stamp (optional) - duration (float): stop time stamp (optional) - speaker: speaker id for normalization (optional; if not given, the filename is used as speaker id) - out_file (
str) – a filename ending in “.h5”
Return type: None- in_file (
-
-
class
xnmt.preproc.LatticeFromPlfExtractor[source]¶ Bases:
xnmt.preproc.Extractor,xnmt.persistence.SerializableCreates node-labeled lattices that can be read by the
LatticeInputReader.The input to this extractor is a list of edge-labeled lattices in PLF format. The PLF format is described here: http://www.statmt.org/moses/?n=Moses.WordLattices It is used, among others, in the Fisher/Callhome Spanish-to-English Speech Translation Corpus (Post et al, 2013).
Persistence¶
This module takes care of loading and saving YAML files. Both configuration files and saved models are stored in the same YAML file format.
The main objects to be aware of are:
Serializable: must be subclassed by all components that are specified in a YAML file.Ref: a reference that points somewhere in the object hierarchy, for both convenience and to realize parameter sharing.Repeat: a syntax for creating a list components with same configuration but without parameter sharing.YamlPreloader: pre-loads YAML contents so that some infrastructure can be set up, but does not initialize components.initialize_if_needed(),initialize_object(): initialize a preloaded YAML tree, taking care of resolving references etc.save_to_file(): saves a YAML file along with registered DyNet parametersLoadSerialized: can be used to load, modify, and re-assemble pretrained models.bare(): create uninitialized objects, usually for the purpose of specifying them as default arguments.RandomParam: a special Serializable subclass that realizes random parameter search.
-
class
xnmt.persistence.Serializable[source]¶ Bases:
yaml.YAMLObjectAll model components that appear in a YAML file must inherit from Serializable. Implementing classes must specify a unique yaml_tag class attribute, e.g.
yaml_tag = "!Serializable"Return the shared parameters of this Serializable class.
This can be overwritten to specify what parameters of this component and its subcomponents are shared. Parameter sharing is performed before any components are initialized, and can therefore only include basic data types that are already present in the YAML file (e.g. # dimensions, etc.) Sharing is performed if at least one parameter is specified and multiple shared parameters don’t conflict. In case of conflict a warning is printed, and no sharing is performed. The ordering of shared parameters is irrelevant. Note also that if a submodule is replaced by a reference, its shared parameters are ignored.
Return type: List[Set[Union[str,Path]]]Returns: objects referencing params of this component or a subcompononent e.g.: return [set([".input_dim", ".sub_module.input_dim", ".submodules_list.0.input_dim"])]
-
save_processed_arg(key, val)[source]¶ Save a new value for an init argument (call from within
__init__()).Normally, the serialization mechanism makes sure that the same arguments are passed when creating the class initially based on a config file, and when loading it from a saved model. This method can be called from inside
__init__()to save a new value that will be passed when loading the saved model. This can be useful when one doesn’t want to recompute something every time (like a vocab) or when something has been passed via implicit referencing which might yield inconsistent result when loading the model to assemble a new model of different structure.Parameters: - key (
str) – name of property, must match an argument of__init__() - val (
Any) – new value; aSerializableor basic Python type or list or dict of these
Return type: None- key (
-
add_serializable_component(name, passed, create_fct)[source]¶ Create a
Serializablecomponent, or a container component with severalSerializable-s.Serializablesub-components should always be created using this helper to make sure DyNet parameters are assigned properly and serialization works properly. The components must also be accepted as init arguments, defaulting toNone. The helper makes sure that components are only created ifNoneis passed, otherwise the passed component is reused.The idiom for using this for an argument named
my_compwould be:def __init__(self, my_comp=None, other_args, ...): ... my_comp = self.add_serializable_component("my_comp", my_comp, lambda: SomeSerializable(other_args)) # now, do something with my_comp ...
Parameters: - name (
str) – name of the object - passed (
Any) – object as passed in the constructor. IfNone, will be created using create_fct. - create_fct (
Callable[[],Any]) – a callable with no arguments that returns aSerializableor a collection ofSerializable-s. When loading a saved model, this same object will be passed via thepassedargument, andcreate_fctis not invoked.
Return type: AnyReturns: reused or newly created object(s).
- name (
-
class
xnmt.persistence.UninitializedYamlObject(data)[source]¶ Bases:
objectWrapper class to indicate an object created by the YAML parser that still needs initialization.
Parameters: data ( Any) – uninitialized object
-
xnmt.persistence.bare(class_type, **kwargs)[source]¶ Create an uninitialized object of arbitrary type.
This is useful to specify XNMT components as default arguments.
__init__()commonly requires DyNet parameters, component referencing, etc., which are not yet set up at the time the default arguments are loaded. In this case, a bare class can be specified with the desired arguments, and will be properly initialized when passed as arguments into a component.Parameters: - class_type (
Type[~T]) – class type (must be a subclass ofSerializable) - kwargs (
Any) – will be passed to class’s__init__()
Return type: ~T
Returns: uninitialized object
- class_type (
-
class
xnmt.persistence.Ref(path=None, name=None, default=1928437192847)[source]¶ Bases:
xnmt.persistence.SerializableA reference to somewhere in the component hierarchy.
Components can be referenced by path or by name.
Parameters: - path (
Union[None,Path,str]) – reference by path - name (
Optional[str]) – reference by name. The name refers to a unique_xnmt_idproperty that must be set in exactly one component.
-
is_required()[source]¶ Return
Trueiff there exists no default value and it is mandatory that this reference be resolved.Return type: bool
- path (
-
class
xnmt.persistence.Path(path_str='')[source]¶ Bases:
objectA relative or absolute path in the component hierarchy.
Paths are immutable: Operations that change the path always return a new Path object.
Parameters: path_str ( str) – path string, with period.as separator. If prefixed by., marks a relative path, otherwise absolute.
-
class
xnmt.persistence.Repeat(times, content)[source]¶ Bases:
xnmt.persistence.SerializableA special object that is replaced by a list of components with identical configuration but not with shared params.
This can be specified anywhere in the config hierarchy where normally a list is expected. A common use case is a multi-layer neural architecture, where layer configurations are repeated many times. It is replaced in the preloader and cannot be instantiated directly.
-
class
xnmt.persistence.SavedFormatString(value, unformatted_value)[source]¶ Bases:
str,xnmt.persistence.Serializable
-
class
xnmt.persistence.FormatString(value, serialize_as)[source]¶ Bases:
str,yaml.YAMLObjectUsed to handle the
{EXP}string formatting syntax. When passed around it will appear like the properly resolved string, but writing it back to YAML will use original version containing{EXP}
-
class
xnmt.persistence.LoadSerialized(filename, path='', overwrite=None)[source]¶ Bases:
xnmt.persistence.SerializableLoad content from an external YAML file.
This object points to an object in an external YAML file and will be replaced by the corresponding content by the YAMLPreloader.
Parameters: - filename (
str) – YAML file name to load from - path (
str) – path inside the YAML file to load from, with.separators. Empty string denotes root. - overwrite (
Optional[List[Dict[str,Any]]]) –allows overwriting parts of the loaded model with new content. A list of path/val dictionaries, where
pathis a path string relative to the loaded sub-object following the syntax ofPath, andvalis a Yaml-serializable specifying the new content. E.g.:[{"path" : "model.trainer", "val":AdamTrainer()}, {"path" : ..., "val":...}]
It is possible to specify the path to point to a new key to a dictionary. If
pathpoints to a list, it’s possible append to that list by usingappend_valinstead ofval.
- filename (
-
class
xnmt.persistence.YamlPreloader[source]¶ Bases:
objectLoads experiments from YAML and performs basic preparation, but does not initialize objects.
Has the following responsibilities:
- takes care of extracting individual experiments from a YAML file
- replaces
!LoadSerializedby loading the corresponding content - resolves kwargs syntax (items from a kwargs dictionary are moved to the owner where they become object attributes)
- implements random search (draws proper random values when
!RandomParamis encountered) - finds and replaces placeholder strings such as
{EXP},{EXP_DIR},{GIT_REV}, and{PID} - copies bare default arguments into the corresponding objects where appropriate.
Typically,
initialize_object()would be invoked by passing the result from theYamlPreloader.-
static
experiment_names_from_file(filename)[source]¶ Return list of experiment names.
Parameters: filename ( str) – path to YAML fileReturn type: List[str]Returns: experiment names occuring in the given file in lexicographic order.
-
static
preload_experiment_from_file(filename, exp_name, resume=False)[source]¶ Preload experiment from YAML file.
Parameters: - filename (
str) – YAML config file name - exp_name (
str) – experiment name to load - resume (
bool) – set to True if we are loading a saved model file directly and want to restore all formatted strings.
Return type: Returns: Preloaded but uninitialized object.
- filename (
-
static
preload_obj(root, exp_name, exp_dir, resume=False)[source]¶ Preload a given object.
Preloading a given object, usually an
xnmt.experiment.ExperimentorLoadSerializedobject as parsed by pyyaml, includes replacing!LoadSerialized, resolvingkwargssyntax, and instantiating random search.Parameters: - root (
Any) – object to preload - exp_name (
str) – experiment name, needed to replace{EXP} - exp_dir (
str) – directory of the corresponding config file, needed to replace{EXP_DIR} - resume (
bool) – if True, keep the formatted strings, e.g. set{EXP}to the value of the previous run if possible
Return type: Returns: Preloaded but uninitialized object.
- root (
-
xnmt.persistence.save_to_file(fname, mod)[source]¶ Save a component hierarchy and corresponding DyNet parameter collection to disk.
Parameters: - fname (
str) – Filename to save to. - mod (
Any) – Component hierarchy.
Return type: None- fname (
-
xnmt.persistence.initialize_if_needed(root)[source]¶ Initialize if obj has not yet been initialized.
This includes parameter sharing and resolving of references.
Parameters: root ( Union[Any,UninitializedYamlObject]) – object to be potentially serializedReturn type: AnyReturns: initialized object
-
xnmt.persistence.initialize_object(root)[source]¶ Initialize an uninitialized object.
This includes parameter sharing and resolving of references.
Parameters: root ( UninitializedYamlObject) – object to be serializedReturn type: AnyReturns: initialized object
-
xnmt.persistence.check_type(obj, desired_type)[source]¶ Checks argument types using isinstance, or some custom logic if type hints from the ‘typing’ module are given.
Regarding type hints, only a few major ones are supported. This should cover almost everything that would be expected in a YAML config file, but might miss a few special cases. For unsupported types, this function evaluates to True. Most notably, forward references such as ‘SomeType’ (with apostrophes around the type) are not supported. Note also that typing.Tuple is among the unsupported types because tuples aren’t supported by the XNMT serializer.
Parameters: - obj – object whose type to check
- desired_type – desired type of obj
Returns: False if types don’t match or desired_type is unsupported, True otherwise.
Reportable¶
Reports gather inputs, outputs, and intermediate computations in a nicely formatted way for convenient manual inspection.
To support reporting, the models providing the data to be reported must subclass Reportable and call
self.report_sent_info(d) with key/value pairs containing the data to be reported at the appropriate times.
If this causes a computational overhead, the boolean compute_report field should queried and extra computations
skipped if this field is False.
Next, a Reporter needs to be specified that supports reports based on the previously created key/value pairs.
Reporters are passed to inference classes, so it’s possible e.g. to report only at the final test decoding, or specify
a special reporting inference object that only looks at a handful of sentences, etc.
Note that currently reporting is only supported at test-time, not at training time.
-
class
xnmt.reports.ReportInfo(sent_info=[], glob_info={})[source]¶ Bases:
objectInfo to pass to reporter
Parameters: - sent_info (
Sequence[Dict[str,Any]]) – list of dicts, one dict per sentence - glob_info (
Dict[str,Any]) – a global dict applicable to each sentence
- sent_info (
-
class
xnmt.reports.Reportable[source]¶ Bases:
objectBase class for classes that contribute information to a report.
Making an arbitrary class reportable requires to do the following:
specify
Reportableas base classcall this super class’s
__init__(), or do@register_xnmt_handlermanuallypass either global info or per-sentence info or both: - call
self.report_sent_info(d)for each sentence, where d is a dictionary containing info to pass on to thereporter
- call
self.report_corpus_info(d)once, where d is a dictionary containing info to pass on to the reporter
- call
-
report_sent_info(sent_info)[source]¶ Add key/value pairs belonging to the current sentence for reporting.
This should be called consistently for every sentence and in order.
Parameters: sent_info ( Dict[str,Any]) – A dictionary of key/value pairs. The keys must match (be a subset of) the arguments in the reporter’screate_sent_report()method, and the values must be of the corresponding types.Return type: None
-
report_corpus_info(glob_info)[source]¶ Add key/value pairs for reporting that are relevant to all reported sentences.
Parameters: glob_info ( Dict[str,Any]) – A dictionary of key/value pairs. The keys must match (be a subset of) the arguments in the reporter’screate_sent_report()method, and the values must be of the corresponding types.Return type: None
-
class
xnmt.reports.Reporter[source]¶ Bases:
objectA base class for a reporter that collects reportable information, formats it and writes it to disk.
-
class
xnmt.reports.ReferenceDiffReporter(match_size=3, alt_norm=False, report_path='{EXP_DIR}/reports/{EXP}')[source]¶ Bases:
xnmt.reports.Reporter,xnmt.persistence.SerializableReporter that uses the CharCut tool for nicely displayed difference highlighting between outputs and references.
The stand-alone tool can be found at https://github.com/alardill/CharCut
Parameters: - match_size (
Integral) – min match size in characters (set < 3 e.g. for Japanese or Chinese) - alt_norm (
bool) – alternative normalization scheme: use only the candidate’s length for normalization - report_path (
str) – Path of directory to write HTML files to
-
create_sent_report(src, output, ref_file=None, **kwargs)[source]¶ Create report.
Parameters: - src (
Sentence) – source-side input - output (
ReadableSentence) – generated output - ref_file (
Optional[str]) – path to reference file - **kwargs – arguments to be ignored
Return type: None- src (
- match_size (
-
class
xnmt.reports.CompareMtReporter(out2_file=None, train_file=None, train_counts=None, alpha=1.0, ngram=4, ngram_size=50, sent_size=10, report_path='{EXP_DIR}/reports/{EXP}')[source]¶ Bases:
xnmt.reports.Reporter,xnmt.persistence.SerializableReporter that uses the compare-mt.py script to analyze and compare MT results.
The stand-alone tool can be found at https://github.com/neubig/util-scripts
Parameters: - out2_file (
Optional[str]) – A path to another system output. Add only if you want to compare outputs from two systems. - train_file (
Optional[str]) – A link to the training corpus target file - train_counts (
Optional[str]) – A link to the training word frequency counts as a tab-separated “wordtfreq” file - alpha (
Real) – A smoothing coefficient to control how much the model focuses on low- and high-frequency events. 1.0 should be fine most of the time. - ngram (
Integral) – Maximum length of n-grams. - sent_size (
Integral) – How many sentences to print. - ngram_size (
Integral) – How many n-grams to print. - report_path (
str) – Path of directory to write report files to
-
create_sent_report(output, ref_file, **kwargs)[source]¶ Create report.
Parameters: - output (
ReadableSentence) – generated output - ref_file (
str) – path to reference file - **kwargs – arguments to be ignored
Return type: None- output (
- out2_file (
-
class
xnmt.reports.HtmlReporter(report_name, report_path='{EXP_DIR}/reports/{EXP}')[source]¶ Bases:
xnmt.reports.ReporterA base class for reporters that produce HTML outputs that takes care of some common functionality.
Parameters: - report_name (
str) – prefix for report files - report_path (
str) – Path of directory to write HTML and image files to
- report_name (
-
class
xnmt.reports.AttentionReporter(max_num_sents=100, report_name='attention', report_path='{EXP_DIR}/reports/{EXP}')[source]¶ Bases:
xnmt.reports.HtmlReporter,xnmt.persistence.SerializableReporter that writes attention matrices to HTML.
Parameters: - max_num_sents (
Optional[Integral]) – create attention report for only the first n sentences - report_name (
str) – prefix for output files - report_path (
str) – Path of directory to write HTML and image files to
-
create_sent_report(src, output, attentions, ref_file, **kwargs)[source]¶ Create report.
Parameters: - src (
Sentence) – source-side input - output (
ReadableSentence) – generated output - attentions (
ndarray) – attention matrices - ref_file (
Optional[str]) – path to reference file - **kwargs – arguments to be ignored
Return type: None- src (
-
add_atts(attentions, src_tokens, trg_tokens, idx, desc='Attentions')[source]¶ Add attention matrix to HTML code.
Parameters: - attentions (
ndarray) – numpy array of dimensions (src_len x trg_len) - src_tokens (
Union[Sequence[str],ndarray]) – list of strings (case of src text) or numpy array of dims (nfeat x speech_len) (case of src speech) - trg_tokens (
Sequence[str]) – list of string tokens - idx (
Integral) – sentence no - desc (
str) – readable description
Return type: None- attentions (
- max_num_sents (
-
class
xnmt.reports.SegmentationReporter(report_path='{EXP_DIR}/reports/{EXP}')[source]¶ Bases:
xnmt.reports.Reporter,xnmt.persistence.SerializableA reporter to be used with the segmenting encoder.
Parameters: report_path ( str) – Path of directory to write text files to
-
class
xnmt.reports.OOVStatisticsReporter(train_trg_file, report_path='{EXP_DIR}/reports/{EXP}')[source]¶ Bases:
xnmt.reports.Reporter,xnmt.persistence.SerializableA reporter that prints OOV statistics: recovered OOVs, fantasized new words, etc.
Some models such as character- or subword-based models can produce words that are not in the training. This is desirable when we produce a correct word that would have been an OOV with a word-based model but undesirable when we produce something that’s not a correct word. The reporter prints some statistics that help analyze the OOV behavior of the model.
Parameters: - train_trg_file (
str) – path to word-tokenized training target file - report_path (
str) – Path of directory to write text files to
- train_trg_file (
Settings¶
Global settings that control the overall behavior of XNMT.
Currently, settings control the following:
OVERWRITE_LOG: whether logs should be overwritten (not overwriting helps when copy-pasting config files and forgetting to change the output location)IMMEDIATE_COMPUTE: whether to execute DyNet in eager modeCHECK_VALIDITY: configure xnmt and DyNet to perform checks of validityRESOURCE_WARNINGS: whether to show resource warningsLOG_LEVEL_CONSOLE: verbosity of console output (DEBUG|INFO|WARNING|ERROR|CRITICAL)LOG_LEVEL_FILE: verbosity of file output (DEBUG|INFO|WARNING|ERROR|CRITICAL)DEFAULT_MOD_PATH: default location to write models toDEFAULT_LOG_PATH: default location to write out logs
There are several predefined configurations (Standard, Debug, Unittest), with Standard being used by
default. Settings are specified from the command line using --settings={standard|debug|unittest} and should not be
changed during execution.
It is possible to control individual settings by setting an environment variable of the same name, e.g. like this:
OVERWRITE_LOG=1 python -m xnmt.xnmt_run_experiments my_config.yaml
To specify a custom configuration, subclass settings.Standard accordinly and add an alias to settings._aliases.
-
class
xnmt.settings.Debug[source]¶ Bases:
xnmt.settings.StandardAdds checks and verbosity to help debugging code or configuration files.
-
class
xnmt.settings.Unittest[source]¶ Bases:
xnmt.settings.StandardMore checks and less verbosity, activated automatically when running the unit tests from the “test” package.